Reflective calculi
This is mostly for my own benefit.
We start with some term-generating functor 

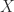
Now specialize to a single ground term:

Now mod out by structural equivalence:

Let 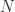


Prequoting and predereference are an algebra and coalgebra of 


such that

Real quoting and dereference have to use 
Define 


so name equivalence is structural equivalence; equivalence of prequoted predereferences is automatic by the definition above.
The fixed point gives us an isomorphism

We can define 

is the identity, satisfying the condition, and

is the identity, which we get for free.
When we mod out by operational semantics (following the traditional approach rather than the 2-categorical one needed for pi calculus):

we have the quotient map

and a map

that picks a representative from the equivalence class.
It’s undecidable whether two terms are in the same operational equivalence class, so 

is the identity.
We can extend prequoting and predereference to quoting and dereference on 


and then




which is what we want for quoting and dereference. The other way around involves undecidability.
Monads without category theory, redux
I intended the last version of this post to be a simple one-off, but people cared too much. A fire-breathing Haskellite said that jQuery must never be used as an example of a monad because it’s (gasp) not even functional! And someone else didn’t understand JavaScript well enough to read my code snippets. So here’s another attempt that acknowledges the cultural divide between functional and imperative programmers and tries to explain everything in English as well as in source code.
Monads are a design pattern that is most useful to functional programmers because their languages prefer to implement features as libraries rather than as syntax. In Haskell there are monads for input / output, side-effects and exceptions, with special syntax for using these to do imperative-style programming. Imperative programmers look at that and laugh: “Why go through all that effort? Just use an imperative language to start with.” Functional programmers also tend to write programs as—surprise!—applying the composite of a bunch of functions to some data. The basic operation for a monad is really just composition in a different guise, so functional programmers find this comforting. Functional programmers are also more likely to use “continuations”, which are something like extra-powerful exceptions that only work well when there is no global state; there’s a monad for making them easier to work with.
There are, however, some uses for monads that even imperative programmers find useful. Collections like sets and lists (with or without parentheses), parsers, promises, and membranes are a few examples, which I’ll explain below.
Collections
Many collection types support the following three operations:
- Map a function over the elements of the collection.
- Flatten a collection of collections into a collection.
- Create a collection from a single element.
A monad is a class that provides a generalized version of these three operations. When I say “generalized”, I mean that they satisfy some of the same rules that the collections’ operations satisfy in much the same way that multiplication of real numbers is associative and commutative just like addition of real numbers.
The way monads are usually used is by mapping a function and then flattening. If we have a function f that takes an element and returns a list, then we can say myList.map(f).flatten() and get a new list.
Parsers
A parser is an object with a list of tokens that have already been parsed and the remainder of the object (usually a string) to be parsed.
var Parser = function (obj, tokens) {
this.obj = obj;
// If tokens are not provided, use the empty list.
this.tokens = tokens || [];
};
It has three operations like the collections above.
- Mapping a function over a parser applies the function to the contained obj.
Parser.prototype.map = function (f) { return new Parser(f(this.obj), this.tokens); }; - Flattening a parser of parsers concatenates the list of tokens.
Parser.prototype.flatten = function () { return new Parser(this.obj.obj, this.obj.tokens.concat(this.tokens)); };The definition above means that
new Parser(new Parser(x, tokens1), tokens2).flatten()
is equivalent tonew Parser(x, tokens1.concat(tokens2)). - We can create a parser from an element
x:new Parser(x).
If we have a function f that takes a string, either parses out some tokens or throws an exception, and returns a parser with the tokens and the remainder of the string, then we can say
myParser.map(f).flatten()
and get a new parser. In what follows, I create a parser with the string “Hi there” and then expect a word, then some whitespace, then another word.
var makeMatcher = function (re) {
return function (s) {
var m = s.match(re);
if (!m) { throw new Error('Expected to match ' + re); }
return new Parser(m[2], [m[1]]);
};
};
var alnum = makeMatcher(/^([a-zA-Z0-9]+)(.*)/);
var whitespace = makeMatcher(/^(s+)(.*)/);
new Parser('Hi there')
.map(alnum).flatten()
.map(whitespace).flatten()
.map(alnum).flatten();
// is equivalent to new Parser('', ['Hi', ' ', 'there']);
Promises
A promise is an object that represents the result of a computation that hasn’t finished yet; for example, if you send off a request over the network for a webpage, the promise would represent the text of the page. When the network transaction completes, the promise “resolves” and code that was waiting on the result gets executed.
- Mapping a function
fover a promise forxresults in a promise forf(x). - When a promise represents remote data, a promise for a promise is still just remote data, so the two layers can be combined; see promise pipelining.
- We can create a resolved promise for any object that we already have.
If we have a function f that takes a value and returns a promise, then we can say
myPromise.map(f).flatten()
and get a new promise. By stringing together actions like this, we can set up a computation that will execute properly as various network actions complete.
Membranes
An object-capability language is an object-oriented programming language where you can’t get a reference to an object unless you create it or someone calls one of your methods and passes a reference to it. A “membrane” is a design pattern that implements access control.
Say you have a folder object with a bunch of file objects. You want to grant someone temporary access to the folder; if you give them a reference to the folder directly, you can’t force them to forget it, so that won’t work for revokable access. Instead, suppose you create a “proxy” object with a switch that only you control; if the switch is on, the object forwards all of its method calls to the folder and returns the results. If it’s off, it does nothing. Now you can give the person the object and turn it off when their time is up.
The problem with this is that the folder object may return a direct reference to the file objects it contains; the person could lose access to the folder but could retain access to some of the files in it. They would not be able to have access to any new files placed in the folder, but would see updates to the files they retained access to. If that is not your intent, then the proxy object should hide any file references it returns behind similar new proxy objects and wire all the switches together. That way, when you turn off the switch for the folder, all the switches turn off for the files as well.
This design pattern of wrapping object references that come out of a proxy in their own proxies is a membrane.
- We can map a function
fover a membrane forxand get a membrane forf(x). - A membrane for a membrane for
xcan be collapsed into a single membrane that checks both switches. - Given any object, we can wrap it in a membrane.
If we have a function f that takes a value and returns a membrane, then we can say
myMembrane.map(f).flatten()
and get a new membrane. By stringing together actions like this, we can set up arbitrary reference graphs, while still preserving the membrane creator’s right to turn off access to his objects.
Conclusion
Monads implement the abstract operations map and flatten, and have an operation for creating a new monad out of any object. If you start with an instance m of a monad and you have a function f that takes an object and returns a monad, then you can say
m.map(f).flatten();
and get a new instance of a monad. You’ll often find scenarios where you repeat that process over and over.
Overloading JavaScript’s dot operator with direct proxies
With the new ECMAScript 6 Proxy object that Firefox has implemented, you can make dot do pretty much anything you want. I made the dot operator in JavaScript behave like Haskell’s bind:
// I'll give a link to the code for lift() later,
// but one thing it does is wrap its input in brackets.
lift(6); // [6]
lift(6)[0]; // 6
lift(6).length; // 1
// lift(6) has no "upto" property
lift(6).upto; // undefined
// But when I define this global function, ...
// Takes an int n, returns an array of ints [0, ..., n-1].
var upto = function (x) {
var r = [], i;
for (i = 0; i < x; ++i) {
r.push(i);
}
return r;
};
// ... now the object lift(6) suddenly has this property
lift(6).upto; // [0,1,2,3,4,5]
// and it automagically maps and flattens!
lift(6).upto.upto; // [0,0,1,0,1,2,0,1,2,3,0,1,2,3,4]
lift(6).upto.upto.length; // 15
To be clear, ECMAScript 6 has changed the API for Proxy since Firefox adopted it, but you can implement the new one on top of the old one. Tom van Cutsem has code for that.
I figured this out while working on a contracts library for JavaScript. Using the standard monadic style (e.g. jQuery), I wrote an implementation that doesn’t use proxies; it looked like this:
lift(6)._(upto)._(upto).value; // [0,0,1,0,1,2,0,1,2,3,0,1,2,3,4]
The lift function takes an input, wraps it in brackets, and stores it in the value property of an object. The other property of the object, the underscore method, takes a function as input, maps that over the current value and flattens it, then returns a new object of the same kind with that flattened array as the new value.
The direct proxy API lets us create a “handler” for a target object. The handler contains optional functions to call for all the different things you can do with an object: get or set properties, enumerate keys, freeze the object, and more. If the target is a function, we can also trap when it’s used as a constructor (i.e. new F()) or when it’s invoked.
In the proxy-based implementation, rather than create a wrapper object and set the value property to the target, I created a handler that intercepted only get requests for the target’s properties. If the target has the property already, it returns that; you can see in the example that the length property still works and you can look up individual elements of the array. If the target lacks the property, the handler looks up that property on the window object and does the appropriate map-and-flatten logic.
I’ve explained this in terms of the list monad, but it’s completely general. In the code below, mon is a monad object defined in the category theorist’s style, a monoid object in an endofunctor category, with multiplication and unit. On line 2, it asks for a type to specialize to. On line 9, it maps the named function over the current state, then applies the monad multiplication. On line 15, it applies the monad unit.
var kleisliProxy = function (mon) {
return function (t) {
var mont = mon(t);
function M(mx) {
return Proxy(mx, {
get: function (target, name, receiver) {
if (!(name in mx)) {
if (!(name in window)) { return undefined; }
return M(mont['*'](mon(window[name]).t(mx)));
}
return mx[name];
}
});
}
return function (x) { return M(mont[1](x)); };
};
};
var lift = kleisliProxy(listMon)(int32);
lift(6).upto.upto; // === [0,0,1,0,1,2,0,1,2,3,0,1,2,3,4]
Formal axiomatic divination
It’s well known that “in Xanadu did Kublai Khan a stately pleasure dome decree,” but his true legacy is the field of formal axiomatic divination. In 1279, Khan sought an auspicious date on which to begin construction of the palace. He consulted each of his twelve astrologers separately and without warning; unsurprisingly, he received twelve different answers. Khan flew into a rage and said that until the astrologer’s craft was as precise as that of his masons and carpenters, they were banished from his presence.
Kublai Khan died in 1294 and his successor Temur Khan was convinced to reinstate the astrologers. Despite this, the young mathematician Zhu Shijie took up the old Khan’s challenge in 1305. Zhu had already completed two enormously influential mathematical texts: Introduction to Mathematical Studies, published in 1299, and True reflections of the four unknowns, published in 1303. This latter work included a table of “the ancient method of powers”, now known as Pascal’s triangle, and Zhu used it extensively in his analysis of polynomials in up to four unknowns.
In turning to the analysis of divination, Zhu naturally focused his attention on the I Ching. The first step in performing an I Ching divination is casting coins or yarrow stalks to construct a series of hexagrams. In 1308, Zhu published his treatise on probability theory, Path of the falling stone. It included an analysis of the probability for generating each hexagram as well as betting strategies for several popular games of chance. Using his techniques, Zhu became quite wealthy and began to travel; it was during this period that he was exposed to the work of the mathematicians in northern China. In the preface to True reflections, Mo Ruo writes that “Zhu Shijie of Yan-shan became famous as a mathematician. He travelled widely for more than twenty years and the number of those who came to be taught by him increased each day.”
Zhu worked for nearly a decade on the subsequent problem, that of interpreting a series of hexagrams. Hexagrams themselves are generated one bit at a time by looking at remainders modulo four of random handfuls of yarrow stalks; the four outcomes either specify the next bit directly or in terms of the previous bit. These latter rules give I Ching its subtitle, The Book of Changes. For mystical reasons, Zhu asserted that the proper interpretation of a series of hexagrams should also be given by a set of changes, but for years he could find no reason to prefer one set of changes to any other. However, in 1316, Zhu wrote to Yang Hui:
“I dreamed that I was summoned to the royal palace. As I stepped upon the threshold, the sun burst forth over the gilded tile; I was blinded and, overcome, I fell to my knees. I lifted my hand to shield my eyes from its brilliance, and the Emperor himself took it and raised me up. To my surprise, he changed his form as I watched; he became so much like me that I thought I was looking in a mirror.
“‘How can this be?’ I cried. He laughed and took the form of a phoenix; I fell back from the flames as he ascended to heaven, then sorrowed as he dove toward the Golden Water River, for the water would surely quench the bird. Yet before reaching the water, he took the form of an eel, dove into the river and swam to the bank; he wriggled ashore, then took the form of a seed, which sank into the earth and grew into a mighty tree. Finally he took his own form again and spoke to me: ‘I rule all things; things above the earth and in the earth and under the earth, land and sea and sky. I can rule all these because I rule myself.’
“I woke and wondered at the singularity of the vision; when my mind reeled in amazement and could stand no more, it retreated to the familiar problem of the tables of changes. It suddenly occurred to me that as the Emperor could take any form, there could be a table of changes that could take the form of any other. Once I had conceived the idea, the implementation was straightforward.”
The rest of the letter has been lost, but Yang Hui described the broad form of the changes in a letter to a friend; the Imperial Changes were a set of changes that we now recognize as a Turing-complete programming language, nearly seven hundred years before Turing. It was a type of register machine similar to Melzak’s model, where seeds were ‘planted’ in pits; the lists of hexagrams generated by the yarrow straws were the programs, and the result of the computation was taken as the interpretation of the casting. Zhu recognized that some programs never stopped–some went into infinite loops, some grew without bound, and some behaved so erratically he couldn’t decide whether they would ever give an interpretation.
Given his fascination with probabilities, it was natural that Zhu would consider the probability that a string of hexagrams had an interpretation. We do not have Zhu’s reasoning, only an excerpt from his conclusion: “The probability that a list of hexagrams has an interpretation is a secret beyond the power of fate to reveal.” It may be that Zhu anticipated Chaitin’s proof of the algorithmic randomness of this probability as well.
All of Zhu’s works were lost soon after they were published; True reflections survived in a corrupted form through Korean (1433 AD) and Japanese (1658 AD) translations and was reintroduced to China only in the nineteenth century. One wonders what the world might have been like had the Imperial Changes been understood and exploited. We suppose it is a secret beyond the power of fate to reveal.
Theories and models
The simplest kind of theory is just a set 




Concepts, however, are usually related to each other, whereas in a set, you can only ask if elements are the same or not. So the way a theory is usually presented is as a category 






Usually, our theories have extra structure. Consider the first example of a model, a function between sets. We can add structure to the theory; for example, we can take the set 
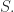




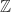

Similarly, we can add structure to a category. If we take monoidal categories 
An element of the set
And there’s no reason to stop at categories; we can consider bicategories with structure and structure-preserving functors between these; these higher theories should let us talk about different models of computation. One model would be Turing machines, another lambda calculus, a third would be the Java Virtual Machine, a fourth Pi calculus.
Renormalization and Computation 4
This is the fourth in a series of posts on Yuri Manin’s pair of papers. In the previous posts, I laid out the background; this time I’ll actually get around to his result.
A homomorphism from the Hopf algebra into a target algebra is called a character. The functor that assigns an action to a path, whether classical or quantum, is a character. In the classical case, it’s into the rig 

Manin mentions that the runtime of a parallel program is a character akin to the classical action, with the runtime of the composition of two programs being the sum of the respective runtimes, while the runtime of two parallel programs is the maximum of the two. A similar result holds for nearly any cost function. He also points out that computably enumerable reals 

In the second paper, he looks at my work with Calude as an example of a character. He uses our same argument to show that lots of measures of program behavior have the property that if the measure hasn’t stopped growing after reaching a certain large amount with respect to the program size, then the density of finite values the measure could take decreases like 
Reading between the lines, he might be suggesting something like approximating the Kolmogorov complexity that he uses later by using a time cutoff, motivated by results from our paper: there’s a constant 
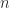


Levin suggested using a computable complexity that’s the sum of the program length and the log of the number of time steps; I suppose you could “regularize” the Kolmogorov complexity by adding 

Instead, he proposed two other constructions suitable for renormalization; here’s the simplest. Given a partial computable function 




When 




The other construction involves turning 

So Manin’s idea of renormalizing the halting problem is to do some uncomputable stuff to get an easy-to-renormalize function and then throw the Birkhoff decomposition at it; since we know the halting problem is undecidable, perhaps the fact that he didn’t come up with a new technique for extracting information about the problem is unsurprising, but after putting in so much effort to understand it, I was left rather disappointed: if you’re going to allow yourself to do uncomputable things, why not just solve the halting problem directly?
I must suppose that his intent was not to tackle this hard problem, but simply to play with the analogy he’d noticed; it’s what I’ve done in other papers. And being forced to learn renormalization was exhilarating! I have a bunch of ideas to follow up; I’ll write them up as I get a chance.
Renormalization and Computation 1
Yuri Manin recently put two papers on the arxiv applying the methods of renormalization to computation and the Halting problem. Grigori Mints invited me to speak on Manin’s results at the weekly Stanford logic seminar because in his second paper, he expands on some of my work.
In these next few posts, I’m going to cover the idea of Feynman diagrams (mostly taken from the lecture notes for the spring 2004 session of John Baez’s Quantum Gravity seminar); next I’ll talk about renormalization (mostly taken from Andrew Blechman’s overview and B. Delamotte’s “hint”); third, I’ll look at the Hopf algebra approach to renormalization (mostly taken from this post by Urs Schreiber on the n-Category Café); and finally I’ll explain how Manin applies this to computation by exploiting the fact that Feynman diagrams and lambda calculus are both examples of symmetric monoidal closed categories (which John Baez and I tried to make easy to understand in our Rosetta stone paper), together with some results on the density of halting times from my paper “Most programs stop quickly or never halt” with Cris Calude. I doubt all of this will make it into the talk, but writing it up will make it clearer for me.
Renormalization is a technique for dealing with the divergent integrals that arise in quantum field theory. The quantum harmonic oscillator is quantum field theory in 0+1 dimensions—it describes what quantum field theory would be like if space consisted of a single point. It doesn’t need renormalization, but I’m going to talk about it first because it introduces the notion of a Feynman diagram.
“Harmonic oscillator” is a fancy name for a rock on a spring. The force exerted by a spring is proportional to how far you stretch it:

The potential energy stored in a stretched spring is the integral of that:

and to make things work out nicely, we’re going to choose 


By choosing units so that 

where 
Next we quantize, getting a quantum harmonic oscillator, or QHO. We set 

![\begin{array}{rl}\displaystyle [x, p]x^n & \displaystyle = xp - px \\ & = (- x i \frac{\partial}{\partial x} + i \frac{\partial}{\partial x} x)x^n \\\ & \displaystyle = -i(nx^n - (n+1)x^n) \\ & \displaystyle = ix^n.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7D%5Cdisplaystyle+%5Bx%2C+p%5Dx%5En+%26+%5Cdisplaystyle+%3D+xp+-+px+%5C%5C+%26+%3D+%28-+x+i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D+%2B+i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D+x%29x%5En+%5C%5C%5C+%26+%5Cdisplaystyle+%3D+-i%28nx%5En+-+%28n%2B1%29x%5En%29+%5C%5C+%26+%5Cdisplaystyle+%3D+ix%5En.%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
If we define a new observable 

We can think of 



The creation operator 



Schrödinger’s equation says 

This way of representing the state of a QHO is known as the “Fock basis”.
Now suppose that we don’t have the ideal system, that the quadratic potential 




Now we solve Schrödinger’s equation perturbatively. We know that

and we assume that

so that it makes sense to solve it perturbatively. Define

and

After a little work, we find that

and integrating, we get

We feed this equation back into itself recursively to get
![\begin{array}{rl}\displaystyle \psi_1(t) & \displaystyle = -i \int_0^t V_1(t_0) \left[-i\int_0^{t_0} V_1(t_1) \psi_1(t_1) dt_1 + \psi(0) \right] dt_0 + \psi(0) \\ & \displaystyle = \left[\psi(0)\right] + \left[\int_0^t i^{-1} V_1(t_0)\psi(0) dt_0\right] + \left[\int_0^t\int_0^{t_0} i^{-2} V_1(t_0)V_1(t_1) \psi_1(t_1) dt_1 dt_0\right] \\ & \displaystyle = \sum_{n=0}^{\infty} \int_{t \ge t_0 \ge \ldots \ge t_{n-1} \ge 0} i^{-n} V_1(t_0)\cdots V_1(t_{n-1}) \psi(0) dt_{n-1}\cdots dt_0 \\ & \displaystyle = \sum_{n=0}^{\infty} (-\lambda i)^n \int_{t \ge t_0 \ge \ldots \ge t_{n-1} \ge 0} e^{-i(t-t_0)H_0} V e^{-i(t_0-t_1)H_0} V \cdots V e^{-i(t_{n-1}-0)H_0} \psi(0) dt_{n-1}\cdots dt_0.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7D%5Cdisplaystyle+%5Cpsi_1%28t%29+%26+%5Cdisplaystyle+%3D+-i+%5Cint_0%5Et+V_1%28t_0%29+%5Cleft%5B-i%5Cint_0%5E%7Bt_0%7D+V_1%28t_1%29+%5Cpsi_1%28t_1%29+dt_1+%2B+%5Cpsi%280%29+%5Cright%5D+dt_0+%2B+%5Cpsi%280%29+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Cleft%5B%5Cpsi%280%29%5Cright%5D+%2B+%5Cleft%5B%5Cint_0%5Et+i%5E%7B-1%7D+V_1%28t_0%29%5Cpsi%280%29+dt_0%5Cright%5D+%2B+%5Cleft%5B%5Cint_0%5Et%5Cint_0%5E%7Bt_0%7D+i%5E%7B-2%7D+V_1%28t_0%29V_1%28t_1%29+%5Cpsi_1%28t_1%29+dt_1+dt_0%5Cright%5D+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Csum_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+%5Cint_%7Bt+%5Cge+t_0+%5Cge+%5Cldots+%5Cge+t_%7Bn-1%7D+%5Cge+0%7D+i%5E%7B-n%7D+V_1%28t_0%29%5Ccdots+V_1%28t_%7Bn-1%7D%29+%5Cpsi%280%29+dt_%7Bn-1%7D%5Ccdots+dt_0+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Csum_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+%28-%5Clambda+i%29%5En+%5Cint_%7Bt+%5Cge+t_0+%5Cge+%5Cldots+%5Cge+t_%7Bn-1%7D+%5Cge+0%7D+e%5E%7B-i%28t-t_0%29H_0%7D+V+e%5E%7B-i%28t_0-t_1%29H_0%7D+V+%5Ccdots+V+e%5E%7B-i%28t_%7Bn-1%7D-0%29H_0%7D+%5Cpsi%280%29+dt_%7Bn-1%7D%5Ccdots+dt_0.%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
So here we have a sum of a bunch of terms; the
Here’s an example Feynman diagram for this simple system, representing the fourth term in the sum above:

The lines represent evolving under the free Hamiltonian
As an example, let’s consider 




A particle moving in a quadratic potential in

The vertices are interactions with the electromagnetic field. The straight lines are electrons and the wiggly ones are photons; between interactions, they propagate under the free Hamiltonian.
Functors and monads
In many languages you have type constructors; given a type A and a type constructor Lift, you get a new type Lift<A>. A functor is a type constructor together with a function
lift: (A -> B) -> (Lift<A> -> Lift<B>)
that preserves composition and identities. If h is the composition of two other functions g and f
h (a) = g (f (a)),
then lift (h) is the composition of lift (g) and lift (f)
lift (h) (la) = lift (g) (lift (f) (la)),
where the variable la has the type Lift<A>. Similarly, if h is the identity function on variables of type A
h (a: A) = a,
then lift (h) will be the identity on variables of type Lift<A>
lift (h) (la) = la.
Examples:
- Multiplication
Lift<>adjoins an extra integer to any type:Lift<A> = Pair<A, int>
The function
lift()pairs upfwith the identity function on integers:lift (f) = (f, id)
- Concatenation
Lift<>adjoins an extra string to any type:Lift<A> = Pair<A, string>
The function
lift()pairs upfwith the identity function on strings:lift (f) = (f, id)
- Composition
LetEnvbe a type representing the possible states of the environment andEffect = Env -> Env
Also, we’ll be explicit in the type of the identity function
id<A>: A -> A id<A> (a) = a,
so one possible
Effectisid<Env>, the “trivial side-effect”.Then
Lift<>adjoins an extra side-effect to any type:Lift<A> = Pair<A, Effect>
The function
lift()pairs upfwith the identity on side-effects:lift (f) = (f, id<Effect>)
- Lists
The previous three examples used the Pair type constructor to adjoin an extra value. This functor is slightly different. Here,Lift<>takes any typeAto a list ofA‘s:Lift<A> = List<A>
The function
lift()is the function map():lift = map
- Double negation, or the continuation passing transform
In a nice type system, there’s theUnittype, with a single value, and there’s also theEmptytype, with no values (it’s “uninhabited”). The only function of typeX -> Emptyis the identity functionid<Empty>. This means that we can think of types as propositions, where a proposition is true if it’s possible to construct a value of that type. We interpret the arrow as implication, and negation can be defined as “arrowing intoEmpty“: letF = EmptyandT = F -> F. ThenT -> F = F(sinceT -> Fis uninhabited) andTis inhabited since we can construct the identity function of type F -> F. Functions correspond to constructive proofs. “Negation” of a proof is changing it into its contrapositive form:If A then B => If NOT B then NOT A.
Double negation is doing the contrapositive twice:
IF A then B => If NOT NOT A then NOT NOT B.
Here,
Lift<>is double negation:Lift<A> = (A -> F) -> F.
The function lift takes a proof to its double contrapositive:
lift: (A -> B) -> ((A -> F) -> F) -> ((B -> F) -> F) lift (f) (k1) (k2) = k1 (lambda (a) { k2 (f (a)) })
Monads
A monad is a functor together with two functions
m: Lift<Lift<A>> -> Lift<A> e: A -> Lift<A>
satisfying some conditions I’ll get to in a minute.
Examples:
- Multiplication
If you adjoin two integers,m()multiplies them to get a single integer:m: Pair<Pair<A, int>, int> -> Pair<A, int> m (a, i, j) = (a, i * j).
The function
e()adjoins the multiplicative identity, or “unit”:e: A -> Pair<A, int> e (a) = (a, 1)
- Concatenation
If you adjoin two strings,m()concatenates them to get a single string:m: Pair<Pair<A, string>, string> -> Pair<A, string> m (a, s, t) = (a, s + t).
The function
e()adjoins the identity for concatenation, the empty string:e: A -> Pair<A, string> e (a) = (a, "")
- Composition
If you adjoin two side-effects,m()composes them to get a single effect:m: Pair<Pair<A, Effect>, Effect> -> Pair<A, Effect> m (a, s, t) = (a, t o s),
where
(t o s) (x) = t (s (x)).
The function
e()adjoins the identity for composition, the identity function onEnv:e: A -> Pair<A, Effect> e (a) = (a, id<Env>)
- Lists
If you have two layers of lists,m()flattens them to get a single layer:m: List<List<A>> -> List<A> m = flatten
The function
e()makes any element of A into a singleton list:e: A -> List<A> e (a) = [a]
- Double negation, or the continuation passing transform
If you have a quadruple negation,m()reduces it to a double negation:m: ((((A -> F) -> F) -> F) -> F) -> ((A -> F) -> F) m (k1) (k2) = k1 (lambda (k3) { k3 (k2) })The function
e()is just reverse application:e: A -> (A -> F) -> F e (a) (k) = k (a)
The conditions that e and m have to satisfy are that m is associative and e is a left and right unit for m. In other words, assume we have
llla: Lift<Lift<Lift<A>>> la: Lift<A>
Then
m (lift (m) (llla)) = m (m (llla))
and
m (e (la)) = m (lift (e) (la)) = la
Examples:
- Multiplication:
There are two different ways we can use lifting with these two extra functionse()andm(). The first is applyinglift()to them. When we applylifttom(), it acts on three integers instead of two; but becauselift (m) = (m, id),
it ignores the third integer:
lift (m) (a, i, j, k) = (a, i * j, k).
Similarly, lifting
e()will adjoin the multiplicative unit, but will leave the last integer alone:lift (e) = (e, id) lift (e) (a, i) = (a, 1, i)
The other way to use lifting with
m()ande()is to applyLift<>AasPair<A', int>, so the first integer gets ignored:m (a, i, j, k) = (a, i, j * k) e (a, i) = (a, i, 1)
Now when we apply
m()to all of these, we get the associativity and unit laws. For associativity we getm (lift (m) (a, i, j, k)) = m(a, i * j, k) = (a, i * j * k) m (m (a, i, j, k)) = m(a, i, j * k) = (a, i * j * k)
and for unit, we get
m (lift (e) (a, i)) = m (a, 1, i) = (a, 1 * i) = (a, i) m (e (a, i)) = m (a, i, 1) = (a, i * 1) = (a, i)
- Concatenation
There are two different ways we can use lifting with these two extra functionse()andm(). The first is applyinglift()to them. When we apply lift tom(), it acts on three strings instead of two; but becauselift (m) = (m, id),
it ignores the third string:
lift (m) (a, s, t, u) = (a, s + t, u).
Similarly, lifting
e()will adjoin the empty string, but will leave the last string alone:lift (e) = (e, id) lift (e) (a, s) = (a, "", s)
The other way to use lifting with
m()ande()is to applyLift<>to their input types. This specifiesAasPair<A', string>, so the first string gets ignored:m (a, s, t, u) = (a, s, t + u) e (a, s) = (a, s, 1)
Now when we apply
m()to all of these, we get the associativity and unit laws. For associativity we getm (lift (m) (a, s, t, u)) = m(a, s + t, u) = (a, s + t + u) m (m (a, s, t, u)) = m(a, s, t + u) = (a, s + t + u)
and for unit, you get
m (lift (e) (a, s)) = m (a, "", s) = (a, "" + s) = (a, s) m (e (a, s)) = m (a, s, "") = (a, s + "") = (a, s)
- Composition
There are two different ways we can use lifting with these two extra functionse()andm(). The first is applyinglift()to them. When we apply lift tom(), it acts on three effects instead of two; but becauselift (m) = (m, id<Effect>),
it ignores the third effect:
lift (m) (a, s, t, u) = (a, t o s, u).
Similarly, lifting
e()will adjoin the identity function, but will leave the last string alone:lift (e) = (e, id<Effect>) lift (e) (a, s) = (a, id<Env>, s)
The other way to use lifting with
m()ande()is to applyLift<>to their input types. This specifiesAasPair<A', Effect>, so the first effect gets ignored:m (a, s, t, u) = (a, s, u o t) e (a, s) = (a, s, id<Env>)
Now when we apply
m()to all of these, we get the associativity and unit laws. For associativity we getm (lift (m) (a, s, t, u)) = m(a, t o s, u) = (a, u o t o s) m (m (a, s, t, u)) = m(a, s, u o t) = (a, u o t o s)
and for unit, you get
m (lift (e) (a, s)) = m (a, id<Env>, s) = (a, s o id<Env>) = (a, s) m (e (a, s)) = m (a, s, id<Env>) = (a, id<Env> o s) = (a, s)
- Lists
There are two different ways we can use lifting with these two extra functionse()andm(). The first is applyinglift()to them. When we apply lift tom(), it acts on three layers instead of two; but becauselift (m) = map (m),
it ignores the third (outermost) layer:
lift (m) ([[[a, b, c], [], [d, e]], [[]], [[x], [y, z]]]) = [[a, b, c, d, e], [], [x, y, z]]
Similarly, lifting
e()will make singletons, but will leave the outermost layer alone:lift (e) ([a, b, c]) = [[a], [b], [c]]
The other way to use lifting with
m()ande()is to applyLift<>to their input types. This specifiesAasList<A'>, so the *innermost* layer gets ignored:m ([[[a, b, c], [], [d, e]], [[]], [[x], [y, z]]]) = [[a, b, c], [], [d, e], [], [x], [y, z]] e ([a, b, c]) = [[a, b, c]]
Now when we apply
m()to all of these, we get the associativity and unit laws. For associativity we getm (lift (m) ([[[a, b, c], [], [d, e]], [[]], [[x], [y, z]]])) = m([[a, b, c, d, e], [], [x, y, z]]) = [a, b, c, d, e, x, y, z] m (m ([[[a, b, c], [], [d, e]], [[]], [[x], [y, z]]])) = m([[a, b, c], [], [d, e], [], [x], [y, z]]) = [a, b, c, d, e, x, y, z]and for unit, we get
m (lift (e) ([a, b, c])) = m ([[a], [b], [c]]) = [a, b, c] m (e ([a, b, c])) = m ([[a], [b], [c]]) = [a, b, c]
Monads in Haskell style, or “Kleisli arrows”
Given a monad (Lift, lift, m, e), a Kleisli arrow is a function
f: A -> Lift<B>,
so the e() function in a monad is already a Kleisli arrow. Given
g: B -> Lift<C>
we can form a new Kleisli arrow
(g >>= f): A -> Lift<C> (g >>= f) (a) = m (lift (g) (f (a))).
The operation >>= is called “bind” by the Haskell crowd. You can think of it as composition for Kleisli arrows; it’s associative, and e() is the identity for bind. e() is called “return” in that context. Sometimes code is less complicated with bind and return instead of m and e.
If we have a function f: A -> B, we can turn it into a Kleisli arrow by precomposing with e():
(e o f): A -> Lift<B> (e o f) (a) = e (f (a)) = return (f (a)).
Example:
- Double negation, or the continuation passing style transform
We’re going to (1) show that the CPS transform of a function takes a continuation and applies that to the result of the function. We’ll also (2) show that for two functionsr, s,CPS (s o r) = CPS (s) >>= CPS (r),
(1) To change a function
f: A -> Binto a Kleisli arrow (i.e. continuized function)CPS (f): A -> (B -> X) -> X, we just compose withe—or in the language of Haskell, wereturnthe result:CPS (f) (a) (k) = return (f (a)) (k) = (e o f) (a) (k) = e (f (a)) (k) = k (f (a))
(2) Given two Kleisli arrows
f: A -> (B -> F) -> F
and
g: B -> (C -> F) -> F,
we can bind them:
(g >>= f) (a) (k) = m (lift (g) (f (a))) (k) // defn of bind = lift (g) (f (a)) (lambda (k3) { k3 (k) }) // defn of m = f (a) (lambda (b) { (lambda (k3) { k3 (k) }) (g (b)) }) // defn of lift = f (a) (lambda (b) { g (b) (k) }), // applicationwhich is just what we wanted.
In particular, if
fandgare really just continuized functionsf = (e o r) g = (e o s)
then
(g >>= f) (a) (k) = f (a) (lambda (b) { g (b) (k) }) // by above = (e o r) (a) (lambda (b) { (e o s) (b) (k) }) // defn of f and g = (e o r) (a) (lambda (b) { k (s (b)) }) // defn of e = (e o r) (a) (k o s) // defn of composition = (k o s) (r (a)) // defn of e = k (s (r (a))) // defn of composition = (e o (s o r)) (a) (k) // defn of e = CPS (s o r) (a) (k) // defn of CPSso
CPS (s) >>= CPS (r) = CPS (s o r).
Great flash tutorial
http://www.kongregate.com/labs
Also http://www.kongregate.com/forums/11/topics/23746 for doing it all with free tools.
Syntactic string diagrams
I hit on the idea of making lambda a node in a string diagram, where its inputs are an antivariable and a term in which the variable is free, and its output is the same term, but in which the variable is bound. This allows a string diagram notation for lambda calculus that is much closer to the syntactical description than the stuff in our Rosetta Stone paper. Doing it this way makes it easy to also do pi calculus and blue calculus.
There are two types, V (for variable) and T (for term). I’ve done untyped lambda calculus, but it’s straightforward to add subscripts to the types V and T to do typed lambda calculus.
There are six function symbols:
Lambda takes an antivariable and a term that may use the corresponding variable.
This turns an antivariable “x” introduced by lambda into the term “x”.
(Application) This takes
and
.
These two mean we can duplicate and delete terms.


The 
I label the upwards arrows out of lambdas with a variable name in parentheses; this is just to assist in matching up the syntactical representation with the string diagram.
In the example, I surround part of the diagram with a dashed line; this is the part to which the
When I do blue calculus this way, there are a few more function symbols and the relations aren’t confluent, but the flavor is very much the same.

String diagrams for untyped lambda calculus

An example calculation
Caja on Yahoo!
Here at Google, I’m working on an open-source project called Caja. The name is Spanish for box or vault, and is pronounced “KA-hah”.
The general idea of Caja could be summed up as “virtual iFrames”. An iFrame is a little webpage stuck inside a bigger one, like a gadget in iGoogle or YAP. Web browsers use a security policy called the “same-domain policy”, which means that only a web page that came from Google’s servers should be allowed to cause changes to your Google-hosted data: you don’t want to allow the “pet turtle” gadget to delete all your email. So the way iGoogle protects your email is by putting the turtle gadget on a different domain, http://gmodules.com.
The same-domain policy does a good job of making it hard for gadgets to work together and a mediocre job of insulating mutually suspicious gadgets from each other; cross-site scripting (XSS) is a constant threat for any web site. Making sure you properly sanitize every use of user-supplied information is like trying to avoid getting a cold while surrounded by forty sniffling kindergarteners.
Also, even if you do manage to prevent XSS entirely, iFrames do nothing to prevent redirecting the page: it’s trivial for a gadget to tell your web browser to go to a page that looks like the Google login page, but really sends your password to the bad guys. All it has to do is include this line of code:
<script>window.top.location = “http://www.evil.com/phishing.html”;</script>
Caja addresses all these issues. On a gadget site like YAP, instead of sending your web browser a page with a bunch of iFrames, each of which causes your web browser to fetch a gadget, Yahoo’s server fetches the gadgets first and rewrites them with Caja, inserting code that looks at every operation the gadget tries to do. It also replaces the objects that code usually has access to, like window above, and replaces them with fake ones. The fake window object doesn’t have a working top.location property, so the gadget can’t redirect the page. The DOM objects sanitize strings passed to innerHTML and remove script blocks, so XSS is impossible. By letting two gadgets see the same variable, they can communicate with each other. Outgoing links are rewritten so that they pass through Yahoo’s proxy server, where the links can be checked in real time for malware.
With the lauch of My Yahoo! and Yahoo! Mail gadgets, we’ve got 275 million users. The best part is that we’re hardly mentioned anywhere: it’s so unobtrusive, that developers don’t even notice the restrictions. (But you can read about Caja on Yahoo’s site.) iGoogle’s sandbox also allows you to play with Caja today; it should go live next month, and we’re hoping to get Caja into several other Google properties as the year progresses.
Blue cell
It’s not immediately obvious how the blue calculus lets you do object references, so here’s a worked example.
I’m going to define a process, called Reference, that takes a new variable and turns it into an object reference. Because it’s easier to type, I’m going to use \ for lambda and v for nu, and when I apply a term to something other than a variable, you’re supposed to do the embedding from lambda calculus into blue calculus in your head. I’m leaving it out because the embedding behaves the same as lambda calculus and things are confusing enough as it is.
Reference = \ref.vc.( c | c = \x.(ref <= Pair c (x | cx)) )
Notice the Pair combinator (Pair = \xyz.zxy); it’s being applied to two processes that function like write and read, respectively, and is waiting for a third; if the third input is K, we get Kxy = x, and if it’s KI, we get KIxy = Iy = y.
You create an object by feeding it a variable for the reference and an initial state:
Reference ref u = vc.(cu | c = \x.(ref <= Pair c (x | cx)))
Now if you have a reference with some state in parallel with a writer process, it updates the state:
(Reference ref u | ref K w)
= ( vc.(cu | c = \x.(ref <= Pair c (x | cx))) | ref K w )
= vc.(cu | c = \x.(ref <= Pair c (x | cx)) | ref K w ) [by scope migration]
= vc.(\x.(ref <= Pair c (x | cx)) u | c = \x.(ref <= Pair c (x | cx)) | ref K w ) [by resource fetching on c]
= vc.(ref <= Pair c (u | cu) | c = \x.(ref <= Pair c (x | cx)) | ref K w ) [by small beta reduction on u]
= vc.(c = \x.(ref <= Pair c (x | cx)) | Pair c (u | cu) K w ) [by resource fetching on ref]
= vc.(c = \x.(ref <= Pair c (x | cx)) | K c (u | cu) w ) [by definition of Pair = \xyz.zxy]
= vc.(c = \x.(ref <= Pair c (x | cx)) | cw ) [by definition of K = \xy.x]
= vc.(cw | c = \x.(ref <= Pair c (x | cx))) [by symmetry of |]
= Reference ref w
Similarly, if you put it in parallel with a reader process,
(Reference ref u | ref KI w x y … z )
= vc.(c = \x.(ref <= Pair c (x | cx)) | K I c (u | cu) w x y … z) [by the same as above]
= vc.(c = \x.(ref <= Pair c (x | cx)) | I (u | cu) w x y … z) [by the definition of K]
= vc.(c = \x.(ref <= Pair c (x | cx)) | (u | cu) w x y … z) [by the definition of I]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | cuwxy…z) [by distributivity]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | \x.(ref <= Pair c (x | cx)) uwxy…z) [by resource fetching on c]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | (ref <= Pair c (u | cu)) wxy…z) [by small beta reduction on u]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | (ref <= Pair c (u | cu))) [by small beta reduction on w, x, y, …, z]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | \x.(ref <= Pair c (x | cx)) u) [by extensionality]
= vc.(c = \x.(ref <= Pair c (x | cx)) | uwxy…z | cu) [by extensionality]
= vc.(cu | c = \x.(ref <= Pair c (x | cx)) | uwxy…z) [by extensionality]
= (Reference ref u | uwxy…z)
Blue calculus
The lambda calculus is a Turing-complete language, but doesn’t handle concurrency very well; in particular, there’s no concept of a reference as opposed to a value. The lambda calculus has three productions:

The first production,
The beta-reduction rule says


![P[P'/x]](https://s0.wp.com/latex.php?latex=P%5BP%27%2Fx%5D&bg=fff&fg=222&s=0&c=20201002)


The part in brackets reads “with
The blue calculus builds this strategy into the language. Here is an application term in the blue calculus:

Blue calculus splits application into four parts, or “processes”:
- a “small” application
in which a term
- a resource assignment
in which a variable
- a new variable declaration
that introduces a new bound variable into scope; and
- a symmetric monoidal product of terms, thought of as “parallel processes”
The monoidal unit here is the “do-nothing” term
.




Blue calculus also splits beta reduction into two parts:
- a “small” beta reduction
if
is free in
- and a resource fetching rule that gets the value of a variable only when it’s needed
.


By splitting things up this way, the blue calculus allows patterns like nondeterministic choice. The blue calculus term

has two valid reductions,

or

It also allows for resource contention; here, the resource assignment acts as a mutex:



The application term 



This allows the blue calculus to subsume both the lambda calculus and the pi calculus in a nice way. Blue terms are formed as follows:

Lambda terms embed like this:
![\begin{array}{rcl} [x] & \Rightarrow & x \\ ~[\lambda x.M] & \Rightarrow & \lambda x.[M] \\ ~[MN] &\Rightarrow & \nu u.([M]u \;|\; (u = [N])) \quad \mbox{where } u \mbox{ does not appear in } M \mbox{ or } N\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5Bx%5D+%26+%5CRightarrow+%26+x+%5C%5C+%7E%5B%5Clambda+x.M%5D+%26+%5CRightarrow+%26+%5Clambda+x.%5BM%5D+%5C%5C+%7E%5BMN%5D+%26%5CRightarrow+%26+%5Cnu+u.%28%5BM%5Du+%5C%3B%7C%5C%3B+%28u+%3D+%5BN%5D%29%29+%5Cquad+%5Cmbox%7Bwhere+%7D+u+%5Cmbox%7B+does+not+appear+in+%7D+M+%5Cmbox%7B+or+%7D+N%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
Pi terms embed like this:
![\begin{array}{rcl} [\bar{u}x_1\ldots x_n] & \Rightarrow & ux_1\ldots x_n \\ ~[ux_1\ldots x_n.P] & \Rightarrow & (u \Leftarrow \lambda x_1\ldots x_n.P) \\ ~[(P \;|\; Q)] & \Rightarrow & ([P] \;|\; [Q]) \\ ~[\nu u.P] & \Rightarrow & \nu u.[P] \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5B%5Cbar%7Bu%7Dx_1%5Cldots+x_n%5D+%26+%5CRightarrow+%26+ux_1%5Cldots+x_n+%5C%5C+%7E%5Bux_1%5Cldots+x_n.P%5D+%26+%5CRightarrow+%26+%28u+%5CLeftarrow+%5Clambda+x_1%5Cldots+x_n.P%29+%5C%5C+%7E%5B%28P+%5C%3B%7C%5C%3B+Q%29%5D+%26+%5CRightarrow+%26+%28%5BP%5D+%5C%3B%7C%5C%3B+%5BQ%5D%29+%5C%5C+%7E%5B%5Cnu+u.P%5D+%26+%5CRightarrow+%26+%5Cnu+u.%5BP%5D+%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
There are reduction rules for scope migration, associativity, distributivity, replication, and so forth; see the paper for more details.
The upshot of all this is that blue calculus variables are really references, and so one can build the whole theory of concurrent objects on top of it.
Objects (in the OOP sense) as lambda terms
Consider some javascripty pseudocode:
aPoint = {x:3, y:4};This is an object that responds to four messages: “x”, “x =”, “y”, “y =”
>> aPoint.x
[ {x:3, y:4}, 3 ]
>> aPoint.y
[ {x:3, y:4}, 4 ]
>> aPoint.x = 15
[ {x:15, y:4}, null ]
>> aPoint.x
[ {x:15, y:4}, 15 ]
An object consists of code and state, and responds to messages; in the process of responding to a message, the object can change its state. In essence, an object is a function
obj:STATE x MESSAGE x INPUTSTATE x OUTPUT
except that objects provide encapsulation: the internal state of the object is never directly accessible; the only way to see or change the state of an object is through the object’s response to messages. So we define an object to be a lambda term of the form
Y ((self, state, message, input)  [
self(new_state(state, message, input)),
result(state, message, input)
]) (initial_state)
[
self(new_state(state, message, input)),
result(state, message, input)
]) (initial_state)
where ‘Y’ is the fixpoint combinator, the notation (x is an alternative notation for 
Let makePoint be the term
Y ((self, state, message, input) [
self(
if (message == "x =") then [ input, state(1) ] else
if (message == "y =") then [ state(0), input ] else
state),
if (message == "x") then state(0) else
if (message == "y") then state(1) else
null
]).
Then aPoint = makePoint([ 3, 4 ]) =
(message, input) [
makePoint(
if (message == "x =") then [ input, 4 ] else
if (message == "y =") then [ 3, input ] else
[ 3, 4 ]),
if (message == "x") then 3 else
if (message == "y") then 4 else
null
].
Combinators as addresses
In linear lambda calculus, you must use each bound variable exactly once in a term. A term with a single bound variable is a full binary tree of applications in which one of the leaves is the bound variable, so it makes sense to ask, “which leaf?”
Three combinators are universal for the free linear lambda calculus on a countable set of types. In the description below, 

- identity
- cut
- braid






A full binary tree of applications is either a leaf or an application of a left subtree to a right subtree. 
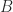
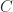

![((C[x\mapsto (r(xs))])t).](https://s0.wp.com/latex.php?latex=%28%28C%5Bx%5Cmapsto+%28r%28xs%29%29%5D%29t%29.&bg=fff&fg=222&s=0&c=20201002)
Now
![((C((Br)[x \mapsto (xs)]))t).](https://s0.wp.com/latex.php?latex=%28%28C%28%28Br%29%5Bx+%5Cmapsto+%28xs%29%5D%29%29t%29.&bg=fff&fg=222&s=0&c=20201002)
Now
![((C((Br)((C[x \mapsto x])s)))t).](https://s0.wp.com/latex.php?latex=%28%28C%28%28Br%29%28%28C%5Bx+%5Cmapsto+x%5D%29s%29%29%29t%29.&bg=fff&fg=222&s=0&c=20201002)
And finally, we replace ![\,[x\mapsto x]](https://s0.wp.com/latex.php?latex=%5C%2C%5Bx%5Cmapsto+x%5D&bg=fff&fg=222&s=0&c=20201002)

to get a term with no bound occurrences of 
![\,[C,B,C,I]](https://s0.wp.com/latex.php?latex=%5C%2C%5BC%2CB%2CC%2CI%5D&bg=fff&fg=222&s=0&c=20201002)
In the (nonlinear) lambda calculus, the variable may appear in either branch or not at all. The 
the variable may appear in either subtree, since
the variable does not appear in this subtree, since
this leaf is a copy of the variable, since



Yoneda embedding as contrapositive and call-cc as double negation
Consider the problem of how to represent negation of a proposition

Since 

The contrapositive says 



What if we don’t even have falsehood? Well, we can pick any proposition

The Yoneda embedding takes a category 


This embedding is better known among computer scientists as the continuation passing style transformation.
In a symmetric monoidal closed category, like lambda calculus, we can move everything “inside:” every morphism 


Here 


To get double negation, first do the Yoneda embedding on the identity to get

then uncurry, braid, and recurry to get

or, internally,

This takes a value

Call-with-current-continuation expects a term that has been converted to CPS style as above, and then hands it the remainder of the computation in

The category GraphUp
The category GraphUp of graphs and Granovetter update rules has
- directed finite graphs as objects
- morphisms generated by Granovetter rules, i.e. the following five operations:
- add a new node. (creation,
refcount=0) - given a node
add a new node
and an edge
(creation,
refcount=1) - given edges
and
add an edge
(introduction,
++refcount) - remove an edge. (deletion,
--refcount) - remove a node and all its outgoing edges if it has no incoming edges. (garbage collection)
- add a new node. (creation,
It’s a monoidal category where the tensor product is disjoint union. Also, since two disjoint graphs can never become connected, they remain disjoint.
Programs in a capability-secure language get interpreted in GraphUp. A program’s state graph consists of nodes, representing the states of the system, and directed edges, representing the system’s transitions between states upon receiving input. A functor from a program state graph to GraphUp assigns an object reference graph as state to each node and an update generated by Granovetter rules to each edge.
Polyadic asynchronous asymmetric pi calculus

where 
Structural congruence:
[with
replacing
(alpha conversion)
(parallel processes)
(association)
(restriction)
(replication)
if

Reduction rules:
[with
replacing
]
- If
then
- If
- If
and
then



Haskell monads for the category theorist
A monad in Haskell is about composing almost-compatible morphisms. Typically you’ve got some morphism 


To define the map of morphisms, we have to define 






To compose “half-functored” morphisms like 



So a “monad” in Haskell is always the monad for categories, except the lists are of bindable half-functored morphisms like 
A side-effect monad has 
Another piece of the stone
A few days ago, I thought that I had understood pi calculus in terms of category theory, and I did, in a way.
|
|
 calculus
calculus calculus
calculusTo make lambda calculus into a category, we mod out by the rewrite rules and consider equivalence classes of terms instead of actual terms. A model of this category (i.e. a functor from the category to Set) picks out a set of values for each datatype and a function for each program. Given a value from the input set, we get a single value from the output set.
Similarly, a model of the pi calculus assigns to each process a set of states and to each reduction rule a function that updates the state. A morphism in this way of thinking is a certain number of reductions to perform. The reductions are deterministic in the sense that we can model “A or B” as 
However, what we really want is to know the set of states it can be in after all the messages have been processed: what is its normal form? This is far more like the rewrite rules in lambda calculus. It suggests that we should be treating the reduction rules like 2-morphisms instead of 1-morphisms. There’s one important difference from lambda calculus, however: the 2-morphisms of pi calculus are not confluent! It matters very much in which order they are evaluated. Thus processes can’t map to anything but trivial functions.
It looks like a better fit for models of the pi calculus is Rel, the category of sets and relations. A morphism in Rel can relate a single input state to multiple output states. This suggests we have a single object * in the pi calculus that gets mapped to a set of possible states for the system, while each process gets mapped to a relation that encodes all its possible reductions.
I’m rather embarrassed that it took me so long to notice this, since my advisor has been talking about replacing Set by Rel for years.
| category | lambda calculus | pi calculus |
| objects | types | only one type *, a system of processes |
| a morphism | an equivalence class of terms | a structural congruence class of processes |
| dinatural transformation from the constant functor (mapping to the terminal set and its identity) to a functor generated by hom, products, projections, and exponentials (if they’re there) | combinator: template for programs mapping between isomorphic types (usually) | since there’s only one type, this is trivial |
| Model of the category in Rel | (usually taken in Set, a subcategory of Rel) a set of values for each data type and a function for each morphism between them | * maps to a set S of states for the system, and each process gets mapped to a relation that relates each element of S to its possible reductions in S |
Continuation passing as a reflection
We can write any expression like 

Figure 1:

[In the caption of figure 1, the expression is slightly different; when using trees, it’s more convenient to curry all the functions—that is, replace every comma “,” by back-to-back parens: “)(” .]
The continuation passing transform (Yoneda embedding) first reflects the tree across the vertical axis and then replaces the root and all the left children with their continuized form—a value


Figure 2:

What does this evaluate to? Well,

As we hoped, it’s the continuization (Yoneda embedding) of the original expression. Iterating, we get

Figure 3:

At this point, we get an enormous simplification: we can get rid of overlines whenever the left and right branch both have them. For instance,

Actually working out the whole expression would mean lots of epicycular reductions like this one, but taking the shortcut, we just get rid of all the lines except at the root. That means that we end up with

for our final expression.
However, if this expression is just part of a larger one—if what we’re calling the “root” is really the child of some other node—then the cancellation of lines on siblings applies to our “root” and its sibling, and we really do get back to where we started!
A piece of the Rosetta stone
| category | lambda calculus | pi calculus | Turing machine |
| objects | types | structural congruence classes of processes |  where where  is the natural numbers and is the natural numbers and  is all binary sequences with finitely many ones. is all binary sequences with finitely many ones. |
| a morphism | an equivalence class of terms | a specific reduction from one process state to the next | a specific transition from one state and position of the machine to the next |
| dinatural transformation from the constant functor (mapping to the terminal set and its identity) to a functor generated by hom, products, projections, and exponentials (if they’re there) | combinator | reduction rule (covers all reductions of a particular form) | tape-head update rule (covers all transitions with the current cell and state in common) |
| products | product types | parallel processes | multiple tapes |
| internal hom | exponential types | all types are exponentials? | ? |
| Model of the category in Set | A set of values for each data type and a function for each morphism between them | A set of states for each process and a single evolution function out of each set. | ? |
This won’t be appearing in our Rosetta stone paper, but I wanted to write it down. What flavor of logic corresponds to the pi calculus? To the Turing machine?
The continuation passing transform and the Yoneda embedding
They’re the same thing! Why doesn’t anyone ever say so?
Assume A and B are types; the continuation passing transform takes a function (here I’m using C++ notation)
B f(A a);
and produces a function
CPT_f( (*k)(B), A a) {
return k(f(a));
}
where X is any type. In CPT_f, instead of returning the value f(a) directly, it reads in a continuation function k and “passes” the result to it. Many compilers use this transform to optimize the memory usage of recursive functions; continuations are also used for exception handling, backtracking, coroutines, and even show up in English.
The Yoneda embedding takes a category

We get the transformation above by uncurrying to get

In Java, a (cartesian closed) category C with a bunch of internal interfaces and methods mapping between them. A functor 
class F implements C.
Then each internal interface C.A gets instantiated as a set F.A of values and each method C.f() becomes instantiated as a function F.f() between the sets.
The continuation passing transform can be seen as a parameterized functor 
class CPT<X> implements C.
Then each internal interface C.A gets instantiated as a set CPT.A of methods mapping from C.A to X—i.e. continuations that accept an input of type C.A—and each method C.f maps to the continuized function CPT.f described above.
Then the Yoneda lemma says that for every model of class F implementing the interface C—there’s a natural isomorphism between the set 

A natural transformation 

F to the class CPT<X> such that for any method of C, you can either
- invoke its implementation directly (as a method of
F) and then continuize the result (using the type cast), or - continuize first (using the type cast) and then invoke the continuized function (as a method of
CPT<X>) on the result
and you’ll get the same answer. Because it’s a natural isomorphism, the cast has an inverse.
The power of the Yoneda lemma is taking a continuized form (which apparently turns up in lots of places) and replacing it with the direct form. The trick to using it is recognizing a continuation when you see one.
Category Theory for the Java Programmer
[Edit May 11, 2012: I’ve got a whole blog on Category Theory in JavaScript.]
There are several good introductions to category theory, each written for a different audience. However, I have never seen one aimed at someone trained as a programmer rather than as a computer scientist or as a mathematician. There are programming languages that have been designed with category theory in mind, such as Haskell, OCaml, and others; however, they are not typically taught in undergraduate programming courses. Java, on the other hand, is often used as an introductory language; while it was not designed with category theory in mind, there is a lot of category theory that passes over directly.
I’ll start with a sentence that says exactly what the relation is of category theory to Java programming; however, it’s loaded with category theory jargon, so I’ll need to explain each part.
A collection of Java interfaces is the free3 cartesian4 category2 with equalizers5 on the interface6 objects1 and the built-in7 objects.
1. Objects
Both in Java and in category theory, objects are members of a collection. In Java, it is the collection of values associated to a class. For example, the class Integer may take values from 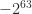

enum Seasons { Spring, Summer, Fall, Winter }
has four possible values.
In category theory, the collection of objects is “half” of a category. The other part of the category is a collection of processes, called “morphisms,” that go between values; morphisms are the possible ways to get from one value to another. The important thing about morphisms is that they can be composed: we can follow a process from an initial value to an intermediate value, and then follow a second process to a final value, and consider the two processes together as a single composite process.
2. Categories
Formally, a category is
- a collection of objects, and
- for each pair of objects
, a set
of morphisms between them
such that
- for each object
contains an identity morphism
- for each triple of objects
and pair of morphisms
and
there is a composite morphism
- for each pair of objects
and morphism
the identitiy morphisms are left and right units for composition:
and
- for each 4-tuple of objects
and triple of morphisms
composition is associative:
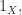
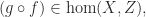

If a morphism 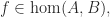
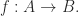
We can also define a category in Java. A category is any implementation of the following interface:
interface Category {
interface Object {}
interface Morphism {}
class IllegalCompositionError extends Error;
Object source(Morphism);
Object target(Morphism);
Morphism identity(Object);
Morphism compose(Morphism, Morphism)
throws IllegalCompositionError;
};
that passes the following tests on all inputs:
void testComposition(Morphism g, Morphism f) {
if (target(f) != source(g)) {
assertRaises(compose(g, f),
IllegalCompositionError);
} else {
assertEqual(source(compose(g, f)), source(f));
assertEqual(target(compose(g, f)), target(g));
}
}
void testAssociativity(Morphism h,
Morphism g,
Morphism f) {
assertEqual(compose(h, compose(g, f)),
compose(compose(h, g), f));
}
void testIdentity(Object x) {
assertEqual(source(identity(x)), x);
assertEqual(target(identity(x)), x);
}
void testUnits(Morphism f) {
assertEqual(f, compose(identity(target(f)), f));
assertEqual(f, compose(f, identity(source(f))));
}
One kind of category that programmers use every day is a monoid. Monoids are sets equipped with a multiplication table that’s associative and has left- and right units. Monoids include everything that’s typically called addition, multiplication, or concatenation. Adding integers, multiplying matrices, concatenating strings, and composing functions from a set to itself are all examples of monoids.
In the language of category theory, a monoid is a one-object category (monos is Greek for “one”). The set of elements you can “multiply” is the set of morphisms from that object to itself.
In Java, a monoid is any implementation of the Category interface that also passes this test on all inputs:
void testOneObject(Morphism f, Object x) {
assertEqual(source(f), x);
}
The testOneObject test says that given any morphism f and any object x, the source of the morphism has to be that object: given another object y, the test says that source(f) == x and source(f) == y, so x == y. Therefore, if the category passes this test, it has only one object.
For example, consider the monoid of XORing bits together, also known as addition modulo 2. Adding zero is the identity morphism for the unique object; we need a different morphism to add 1:
interface Parity implements Category {
Morphism PlusOne();
}
The existence of the PlusOne method says that there has to be a distinguished morphism, which could potentially be different from the identity morphism. The interface itself can’t say how that morphism should behave, however. We need tests for that. The testPlusOne test says that (1 + 1) % 2 == 0. The testOneIsNotZero test makes sure that we don’t just set 1 == 0: since (0 + 0) % 2 == 0, the first test isn’t enough to catch this case.
void testOnePlusOne(Object x) {
assertEqual(compose(PlusOne(), PlusOne()),
identity(x));
}
void testOneIsNotZero(Object x) {
assertNotEqual(PlusOne(), identity(x));
}
Here’s one implementation of the Parity interface that passes all of the tests for Category, testOneObject, and the two Parity tests:
class ParityImpl implements Parity {
enum ObjectImpl implements Object { N };
enum MorphismImpl implements Morphism {
PlusZero,
PlusOne
};
Object source(Morphism) { return N; }
Object target(Morphism) { return N; }
Morphism identity(Object) { return PlusZero; }
Morphism compose(Morphism f, Morphism g) {
if (f == PlusZero) return g; // 0 + g = g
if (g == PlusZero) return f; // f + 0 = f
return PlusZero; // 1 + 1 = 0
}
Morphism PlusOne() { return PlusOne; }
}
3. Free
Java tests are a kind of “blacklisting” approach to governing implementations. Had we not added testOneIsNotZero, we could have returned PlusZero and the compiler would have been happy. In a free category, relations are “whitelisted:” an implementation must not have relations (constraints) other than the ones that are implied by the definitions.
- “The free category” has no objects and no morphisms, because there aren’t any specified.
- “The free category on one object
The morphism has to be there, because the definition of category says that every object has to have an identity morphism, but we can’t put in any other morphisms.
- “The free category on the directed graph
A -f-> B | / G = h g | / V L Chas
- three objects
and
- seven morphisms:
,
,
,
,
,
, and
.
The three vertices and the three edges become objects and morphisms, respectively. The three identity morphisms and
are required to be there because of the definition of a category. And because the category is free, we know that
For abritrary directed graphs, the free category on the graph has the vertices of the graph as objects and the paths in the graph as morphisms.
- three objects
- The parity monoid is completely defined by “the free category on one object
and one relation
“
- If we leave out the relation and consider “the free category on one object
we form
- Exercise: what is the common name for “the free category on one object
?” What should the identity morphism be named?

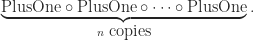
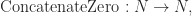
4. Cartesian
A cartesian category has lists as its objects. It has a way to put objects together into ordered pairs, a way to copy objects, and an object that’s “the empty” object.
It’s time to do the magic! Recall the interface Category:
interface Category {
interface Object {}
interface Morphism {}
class IllegalCompositionError extends Error;
Object source(Morphism);
Object target(Morphism);
Morphism identity(Object);
Morphism compose(Morphism, Morphism)
throws IllegalCompositionError;
};
Now let’s change some names:
interface Interface {
interface InternalInterfaceList {}
interface ComposableMethodList {}
class IllegalCompositionError extends Error;
InternalInterfaceList source(ComposableMethodList);
InternalInterfaceList target(ComposableMethodList);
ComposableMethodList identity(InternalInterfaceList);
ComposableMethodList compose(ComposableMethodList,
ComposableMethodList)
throws IllegalCompositionError;
}
Category theory uses cartesian categories to describe structure; Java uses interfaces. Whenever you see “cartesian category,” you can think “interface.” They’re pretty much the same thing. Practically, that means that a lot of the drudgery of implementing the Category interface is taken care of by the Java compiler.
For example, recall the directed graph
interface G {
interface A;
interface B;
interface C;
B f(A);
C g(B);
C h(A);
}
That’s it! We’re considering the free category on 
Because the objects of the cartesian category Interface are lists, we can define methods in our interfaces that have multiple inputs.
interface Monoid {
interface M;
M x(M, M);
M e();
}
void testX(M a, M b, Mc) {
assertEqual(x(a, x(b, c)),
x(x(a, b), c));
}
void testE(M a) {
assertEqual(a, x(a, e()));
assertEqual(a, x(e(), a));
}
Here, the method x takes a two-element list as input, while e takes an empty list.
Exercise: figure out how this definition of a monoid relates to the one I gave earlier.
Implementation as a functor
Cartesian categories (interfaces) provide the syntax for defining data structures. The meaning, or semantics, of Java syntax comes from implementing an interface.
In category theory, functors give meaning to syntax. Functors go between categories like functions go between sets. A functor
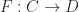
- maps objects of
and
- maps morphisms of
- identities and composition are preserved.
There are several layers of functors involved in implementing a typical Java program. First there’s the implementation of the interface in Java as a class that defines everything in terms of the built-in classes and their methods; next, there’s the implementation of the built-in methods in the Java VM, then implementation of the bytecodes as native code on the machine, and finally, physical implementation of the machine in silicon and electrons. The composite of all these functors is supposed to behave like a single functor into 
The upshot of all this is that a Java class F implementing an interface X can be thought of as a functor 
Here’s an example of three different classes that implement the Monoid interface from the last subsection. Recall that a monoid is a set of things that we can combine; we can add two integers to get an integer, multiply two doubles to get a double, or concatenate two strings to get a string. The combining operation is associative and there’s a special element that has no effect when you combine it with something else: adding zero, multiplying by 1.0, or concatenating the empty string all do nothing.
So, for example,
class AddBits implements Monoid {
enum Bit implements M { Zero, One }
M x(M f, M g) {
if (f == e()) return g; // 0+g=g
if (g == e()) return f; // f+0=f
return Zero; // 1+1=0
}
M e() { return Zero; }
}
Here, the functor 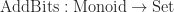
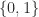

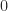
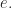
class MultiplyBits implements Monoid {
enum Bit implements M { Zero, One }
M x(M f, M g) {
if (f == e()) return g; // 1*g=g
if (g == e()) return f; // f*1=f
return Zero; // 0*0=0
}
M e() { return One; }
}
Here, the functor 
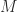

class Concatenate implements Monoid {
class ConcatString implements M {
ConcatString(String x) {
this.x = x;
}
String x;
}
M x(M f, M g) {
return new ConcatString(
f.x + g.x);
}
M e() {
return new ConcatString("");
}
}
Here, the functor 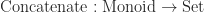
5. Equalizers
An equalizer of two functions 
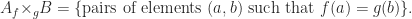
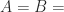
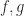
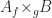
In Java, this means that we can throw an exception if the pair isn’t composable.
6, 7. Interface objects and built-in objects
The objects of the free category in question are java interfaces, whether defined by the programmer or built-in. Because it’s cartesian, we can combine interfaces into new interfaces:
interface XYPair { interface X; interface Y; }
The built-in objects have some relations between them–we can cast an integer into a double, for instance, or turn an integer into a string–so these relations exist between combinations of arbitrary interfaces with built-in ones. But there are no automatic cast relationships between user-defined interfaces, so the category is free.
Next time
This post was about how to translate between Java ideas and category-theory ideas. Next time, I’ll show what category theory has to offer to the Java programmer.
Cellular automaton for land combat
This CA was developed to simulate land combat and presented in a Smithsonian lecture. Really cool pictures.
Universality of nonlinear media
Here’s a neat paper comparing cellular automata and solitons in several different nonlinear media.
Greasemonkey closures
I’m writing up a greasemonkey script that adds onclick behavior to the span. According to the site, you do something like
thisDiv.addEventListener('click',function(){
// function code here
},true);
This works OK, but what if my code needs scope? Say I wanted to search for some divs and have them tell which match they are when clicked. This code won’t work:
for(i=0; i<allDivs.snapshotLength; i++){
var thisDiv=allDivs.getSnapshotItem(i);
thisDiv.addEventListener('click',function(){
alert(i);
},true);
}
If there were 10 matching divs, this will alert “10” every time. On the other hand, this code will work:
for(i=0; i<allDivs.snapshotLength; i++){
var thisDiv=allDivs.getSnapshotItem(i);
thisDiv.addEventListener('click',(function(i){return function(){
alert(i);
};)(i),true);
}
This is helpful when you want your modifications to retain access to functions like GM_setValue without using unsafeWindow. This way won’t work:
for(i=0; i<allDivs.snapshotLength; i++){
var thisDiv=allDivs.getSnapshotItem(i);
thisDiv.addEventListener('click',function(){
GM_setValue('mydata',i);
},true);
}
This way will:
for(i=0; i<allDivs.snapshotLength; i++){
var thisDiv=allDivs.getSnapshotItem(i);
thisDiv.addEventListener('click',(function(i,GM_setValue){return function(){
GM_setValue('mydata',i);
};)(GM_setValue,i),true);
}
Quantum lambda calculus, symmetric monoidal closed categories, and TQFTs
The last post was all about stuff that’s already known. I’ll be working in my thesis on describing the syntax of what I’ll call simply-typed quantum lambda calculus. Symmetric monoidal closed categories (SMCCs) are a generalization of CCCs; they have tensor products instead of products. One of the immediate effects is the lack of built-in projection morphisms 

The typical CCC in which models of a lambda theory are interpreted is Set. The typical SMCC in which models of a quantum lambda theory will be interpreted is Hilb, the category of Hilbert spaces and linear transformations between them. Models of lambda theories correspond to functors from the CCC arising from the theory into Set. Similarly, models of a quantum lambda theory should be functors from a SMCC to Hilb.
Two-dimensional topological quantum field theories (TQFTs) are close to being a model of a quantum lambda theory, but not quite.
There’s a simpler syntax than the simply-typed lambda calculus, called universal algebra, in which one writes algebraic theories. These give rise to categories with finite products (no exponentials) , and functors from these categories to Set pick out sets with the given structure. There’s an algebraic theory of groups, and the functors pick out sets with functions that behave like unit, inverse, and multiplication. So our “programs” consist solely of operations on our data type.
TQFTs are functors from 2Cob, the theory of a commutative Frobenius algebra, to Hilb. We can look at 2Cob as defining a data type and a TQFT as a quantum implementation of the type. When we take the free SMCC over 2Cob, we ought to get a full-fledged quantum programming language with a commutative Frobenius algebra data type. A TQFT would be part of the implementation of the language.
CCCs and lambda calculus
I finally got it through my thick skull what the connection is between lambda theories and cartesian closed categories.
The lambda theory of a set has a single type, with no extra terms or axioms. This gives rise to a CCC where the objects are generated by products and exponentials of a distinguished object, the free CCC on one object. For example, from a type 






The functor itself, however, can be uncomputable: one could, for example, have
When we have types and axioms involved, then we add structure to the set, constraints that the sets and functions on them have to satisfy. For instance, in the lambda theory of groups, we have:
- a type
- terms
- axioms for right- and left-unit laws, right-and left-inverses, and associativity



The CCC arising from this theory has all the morphisms from the free CCC on one object and extra morphisms arising from products and compositions of the terms. A structure-preserving functor to Set assigns 

So in terminology programmers are more familiar with, the terms and axioms define an abstract data type, an interface. The functor gives a class implementing the interface. But this implementation doesn’t need to be computable! Here’s another example: we start with a lambda theory with a data type 



I think that in order to get a computable model, we have to use a “computability functor” (my term). If I’m right, this means that instead of taking a functor directly into Set, we have to take a functor into a CCC with no extra terms to get a “computable theory” (again, my term), and then another from there into Set. This way, since all the morphisms in the category arising from the computable theory are built out of S and K combinators, the functor has to pick an explicit program for the implementation, not just an arbitrary function. From there, whether the implementation of the S and K combinators is computable or not really doesn’t matter; we can’t get at anything uncomputable from within the language.
Now, changing gears and looking at the “programs as proofs” aspect of all this: morphisms in the free CCC on one object are proofs in a minimal intuitionistic logic, where
A computable theory wouldn’t add any axioms, just assign names to proofs so they can be used as subproofs. And because the programs already satisfy the axioms of the computable theory, asserting the equivalence of two proofs is redundant: they’re already equivalent.

leave a comment