Another piece of the stone
A few days ago, I thought that I had understood pi calculus in terms of category theory, and I did, in a way.
|
|
 calculus
calculus calculus
calculusTo make lambda calculus into a category, we mod out by the rewrite rules and consider equivalence classes of terms instead of actual terms. A model of this category (i.e. a functor from the category to Set) picks out a set of values for each datatype and a function for each program. Given a value from the input set, we get a single value from the output set.
Similarly, a model of the pi calculus assigns to each process a set of states and to each reduction rule a function that updates the state. A morphism in this way of thinking is a certain number of reductions to perform. The reductions are deterministic in the sense that we can model “A or B” as 
However, what we really want is to know the set of states it can be in after all the messages have been processed: what is its normal form? This is far more like the rewrite rules in lambda calculus. It suggests that we should be treating the reduction rules like 2-morphisms instead of 1-morphisms. There’s one important difference from lambda calculus, however: the 2-morphisms of pi calculus are not confluent! It matters very much in which order they are evaluated. Thus processes can’t map to anything but trivial functions.
It looks like a better fit for models of the pi calculus is Rel, the category of sets and relations. A morphism in Rel can relate a single input state to multiple output states. This suggests we have a single object * in the pi calculus that gets mapped to a set of possible states for the system, while each process gets mapped to a relation that encodes all its possible reductions.
I’m rather embarrassed that it took me so long to notice this, since my advisor has been talking about replacing Set by Rel for years.
| category | lambda calculus | pi calculus |
| objects | types | only one type *, a system of processes |
| a morphism | an equivalence class of terms | a structural congruence class of processes |
| dinatural transformation from the constant functor (mapping to the terminal set and its identity) to a functor generated by hom, products, projections, and exponentials (if they’re there) | combinator: template for programs mapping between isomorphic types (usually) | since there’s only one type, this is trivial |
| Model of the category in Rel | (usually taken in Set, a subcategory of Rel) a set of values for each data type and a function for each morphism between them | * maps to a set S of states for the system, and each process gets mapped to a relation that relates each element of S to its possible reductions in S |

Continuation passing as a reflection
We can write any expression like 

Figure 1:

[In the caption of figure 1, the expression is slightly different; when using trees, it’s more convenient to curry all the functions—that is, replace every comma “,” by back-to-back parens: “)(” .]
The continuation passing transform (Yoneda embedding) first reflects the tree across the vertical axis and then replaces the root and all the left children with their continuized form—a value 


Figure 2:

What does this evaluate to? Well,

As we hoped, it’s the continuization (Yoneda embedding) of the original expression. Iterating, we get

Figure 3:

At this point, we get an enormous simplification: we can get rid of overlines whenever the left and right branch both have them. For instance,

Actually working out the whole expression would mean lots of epicycular reductions like this one, but taking the shortcut, we just get rid of all the lines except at the root. That means that we end up with

for our final expression.
However, if this expression is just part of a larger one—if what we’re calling the “root” is really the child of some other node—then the cancellation of lines on siblings applies to our “root” and its sibling, and we really do get back to where we started!
A piece of the Rosetta stone
| category | lambda calculus | pi calculus | Turing machine |
| objects | types | structural congruence classes of processes |  where where  is the natural numbers and is the natural numbers and  is all binary sequences with finitely many ones. is all binary sequences with finitely many ones. |
| a morphism | an equivalence class of terms | a specific reduction from one process state to the next | a specific transition from one state and position of the machine to the next |
| dinatural transformation from the constant functor (mapping to the terminal set and its identity) to a functor generated by hom, products, projections, and exponentials (if they’re there) | combinator | reduction rule (covers all reductions of a particular form) | tape-head update rule (covers all transitions with the current cell and state in common) |
| products | product types | parallel processes | multiple tapes |
| internal hom | exponential types | all types are exponentials? | ? |
| Model of the category in Set | A set of values for each data type and a function for each morphism between them | A set of states for each process and a single evolution function out of each set. | ? |
This won’t be appearing in our Rosetta stone paper, but I wanted to write it down. What flavor of logic corresponds to the pi calculus? To the Turing machine?
The continuation passing transform and the Yoneda embedding
They’re the same thing! Why doesn’t anyone ever say so?
Assume A and B are types; the continuation passing transform takes a function (here I’m using C++ notation)
B f(A a);
and produces a function
CPT_f( (*k)(B), A a) {
return k(f(a));
}
where X is any type. In CPT_f, instead of returning the value f(a) directly, it reads in a continuation function k and “passes” the result to it. Many compilers use this transform to optimize the memory usage of recursive functions; continuations are also used for exception handling, backtracking, coroutines, and even show up in English.
The Yoneda embedding takes a category 


We get the transformation above by uncurrying to get

In Java, a (cartesian closed) category 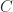
C with a bunch of internal interfaces and methods mapping between them. A functor 
class F implements C.
Then each internal interface C.A gets instantiated as a set F.A of values and each method C.f() becomes instantiated as a function F.f() between the sets.
The continuation passing transform can be seen as a parameterized functor 
class CPT<X> implements C.
Then each internal interface C.A gets instantiated as a set CPT.A of methods mapping from C.A to X—i.e. continuations that accept an input of type C.A—and each method C.f maps to the continuized function CPT.f described above.
Then the Yoneda lemma says that for every model of class F implementing the interface C—there’s a natural isomorphism between the set 

A natural transformation 

F to the class CPT<X> such that for any method of C, you can either
- invoke its implementation directly (as a method of
F) and then continuize the result (using the type cast), or - continuize first (using the type cast) and then invoke the continuized function (as a method of
CPT<X>) on the result
and you’ll get the same answer. Because it’s a natural isomorphism, the cast has an inverse.
The power of the Yoneda lemma is taking a continuized form (which apparently turns up in lots of places) and replacing it with the direct form. The trick to using it is recognizing a continuation when you see one.

leave a comment