HDRA part 1a
Again, comments are appreciated.
2-categories and lambda calculus
This is a follow up post, but not the promised sequel, from A 2-Categorical Approach to the Pi Calculus where I’ll try to correct various errors I made and try to clarify some things.
First, lambda calculus was invented by Church to solve Hilbert’s decision problem, also known as the Entscheidungsproblem. The decision problem was third on a list of problems he presented at a conference in 1928, but was not, as I wrote last time, “Hilbert’s third problem”, which was third on a list of problems he laid out in 1900.
Second, the problem Greg Meredith and I were trying to address was how to prevent reduction under a “receive” prefix in the pi calculus, which is intimately connected with preventing reduction under a lambda in lambda calculus. All programming languages that I know of, whether eager or lazy, do not reduce under a lambda.
There are two approaches in literature to the semantics of lambda calculus. The first is denotational semantics, which was originally concerned with what function a term computes. This is where computability and type theory live. Denotational semantics treats alpha-beta-eta equivalence classes of lambda terms as morphisms in a category. The objects in the category are called “domains”, and are usually “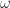
The type of a term describes the structure of its normal form. Values are terms that have no beta reduction; they’re either constants or lambda abstractions. The types in lambda calculus are either base types or lambda abstractions, respectively. (While Lambek and Scott introduced new term constructors for products, they’re not strictly necessary, because the lambda term 



The second is operational semantics, which is more concerned with how a function is computed than what it computes. All of computational complexity theory and algorithmic analysis lives here, since we have to count the number of steps it takes to complete a computation. Operational semantics treats lambda terms as objects in a category and rewrite rules as morphisms. It is a very syntactical approach; the set of terms is an algebra of some endofunctor, usually presented in Backus-Naur Form. This set of terms is then equipped with some equivalence relations and reduction relations. For lambda calculus, we mod out terms by alpha, but not beta. The reduction relations often involve specifying a reduction context, which means that the rewrites can’t occur just anywhere in a term.
In pi calculus, terms don’t have a normal form, so we can’t define an equivalence on pi calculus terms by comparing their normal forms. Instead, we say two terms are equivalent if they behave the same in all contexts, i.e. they’re bisimilar. Typing becomes rather more complicated; pi calculus types describe the structure of the current term and rewrites should do something weaker than preserve types on the nose; it suggests using a double category, but that’s for next time.
Seely suggested modeling rewrites with 2-morphisms in a 2-category and showed how beta and eta were lax adjoints. We’re suggesting a different, more operational way of modeling rewrites with 2-morphisms. Define a 2-category 
and
as generating objects,
and
as generating 1-morphisms,
- alpha equivalence as an identity 2-morphism, and
- beta reduction as a generating 2-morphism.

A closed term is one with no free variables, and the hom category 
The 2-category 
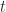



To cut down the extra 2-morphisms, we need to model reduction contexts. The difference between the precontexts above and the contexts we need is the notion of the “topmost” context, where we can see enough of the surrounding term to determine that reduction is possible. To model a reduction context, we make a new 2-category 
![\displaystyle [-]\colon T \to T](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B-%5D%5Ccolon+T+%5Cto+T+&bg=fff&fg=222&s=0&c=20201002)
and say that a 1-morphism with signature 
![[-]](https://s0.wp.com/latex.php?latex=%5B-%5D&bg=fff&fg=222&s=0&c=20201002)
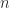

In the next post, I’ll relate Seely’s 2-categorical approach and our 2-categorical by extending to double categories and using Melliès and Zeilberger’s notion of type refinement.
HDRA
Greg Meredith and I have a short paper that’s been accepted to Higher-Dimensional Rewriting and Applications
(HDRA) 2015 on modeling the asynchronous polyadic pi calculus with 2-categories. We avoid domain theory entirely and model the operational semantics directly; full abstraction is almost trivial. As a nice side-effect, we get a new tool for reasoning about consumption of resources during a computation.
It’s a small piece of a much larger project, which I’d like to describe here in a series of posts. This post will talk about lambda calculus for a few reasons. First, lambda calculus is simpler, but complex enough to illustrate one of our fundamental insights. Lambda calculus is to serial computation what pi calculus is to concurrent computation; lambda calculus talks about a single machine doing a computation, while pi calculus talks about a network of machines communicating over a network with potentially random delays. There is at most one possible outcome for a computation in the lambda calculus, while there are many possible outcomes in a computation in the pi calculus. Both the lazy lambda calculus and the pi calculus, however, have as an integral part of their semantics the notion of waiting for a sub-computation to complete before moving onto another one. Second, the denotational semantics of lambda calculus in Set is well understood, as is its generalization to cartesian closed categories; this semantics is far simpler than the denotational semantics of pi calculus and serves as a good introduction. The operational semantics of lambda calculus is also simpler than that of pi calculus and there is previous work on modeling it using higher categories.
History
Alonzo Church invented the lambda calculus as part of his attack on Hilbert’s third problem, also known as the Entscheidungsproblem, which asked for an algorithm to solve any mathematical problem. Church published his proof that no such algorithm exists in 1936. Turing invented his eponymous machines, also to solve the Entscheidungsproblem, and published his independent proof a few months after Church. When he discovered that Church had beaten him to it, Turing proved in 1937 that the two approaches were equivalent in power. Since Turing machines were much more “mechanical” than the lambda calculus, the development of computing machines relied far more on Turing’s approach, and it was only decades later that people started writing compilers for more friendly programming languages. I’ve heard it quipped that “the history of programming languages is the piecemeal rediscovery of the lambda calculus by computer scientists.”
The lambda calculus consists of a set of “terms” together with some relations on the terms that tell how to “run the program”. Terms are built up out of “term constructors”; in the lambda calculus there are three: one for variables, one for defining functions (Church denoted this operation with the Greek letter lambda, hence the name of the calculus), and one for applying those functions to inputs. I’ll talk about these constructors and the relations more below.
Church introduced the notion of “types” to avoid programs that never stop. Modern programming languages also use types to avoid programmer mistakes and encode properties about the program, like proving that secret data is inaccessible outside certain parts of the program. The “simply-typed” lambda calculus starts with a set of base types and takes the closure under the binary operation 
The search for a semantics for variants of the lambda calculus has typically been concerned with finding sets or “domains” such that the interpretation of each lambda term is a function between domains. Scott worked out a domain 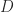
Lambek and Scott constructed a CCC out of lambda terms; we call this category the syntactical category. Then a structure-preserving functor from the syntactical category to Set or some other CCC would provide the semantics. The syntactical category has types as objects and equivalence classes of certain terms as morphisms. A morphism in the syntactical category goes from a typing context to the type of the term.
John Baez has a set of lecture notes from Fall 2006 through Spring 2007 describing Lambek and Scott’s approach to the category theory of lambda calculus and generalizing it from cartesian closed categories to symmetric monoidal closed categories so it can apply to quantum computation as well: rather than taking a functor from the syntactical category into Set, we can take a functor into Hilb instead. He and I also have a “Rosetta stone” paper summarizing the ideas and connecting them with the corresponding generalization of the Curry-Howard isomorphism.
The Curry-Howard isomorphism says that types are to propositions as programs are to proofs. In practice, types are used in two different ways: one as propositions about data and the other as propositions about code. Programming languages like C, Java, Haskell, and even dynamically typed languages like JavaScript and Python use types to talk about propositions that data satisfies: is it a date or a name? In these languages, equivalence classes of programs constitute constructive proofs. Concurrent calculi are far more concerned about propositions that the code satisfies: can it reach a deadlocked state? In these languages, it is the rewrite rules taking one term to another that behave like proofs. Melliès and Zeilberger’s excellent paper “Functors are Type Refinement Systems” relates these two approaches to typing to each other.
Note that Lambek and Scott’s approach does not have the sets of terms or variables as objects! The algebra that defines the set of terms plays only a minor role in the category; there’s no morphism in the CCC, for instance, that takes a term 

The last few decades have seen domains becoming more and more complicated in order to try to “unerase” the information about the structure of terms that gets lost in the domain theory approach and recover the operational semantics. Fiore, Moggi, and Sangiorgi, Stark and Cattani, Stark, and Winskel all present domain models of the pi calculus that recursively involve the powerset in order to talk about all the possible futures for a term. Industry has never cared much about denotational semantics: the Java Virtual Machine is an operational semantics for the Java language.
What we did
Greg Meredith and I set out to model the operational semantics of the pi calculus directly in a higher category rather than using domain theory. An obvious first question is, “What about types?” I was particularly worried about how to relate this approach to the kind of thing Scott and Lambek did. Though it didn’t make it into the HDRA paper and the details won’t make it into this post, we found that we’re able to use the “type-refinement-as-a-functor” idea of Melliès and Zeilberger to show how the algebraic term-constructor functions relate to the morphisms in the syntactical category.
We’re hoping that this categorical approach to modeling process calculi will help with reasoning about practical situations where we want to compose calculi; for instance, we’d like to put a hundred pi calculus engines around the edges of a chip and some ambient calculus engines, which have nice features for managing the location of data, in the middle to distribute work among them.
Lambda calculus
The lambda calculus consists of a set of “terms” together with some relations on the terms. The set 



The term constructors define an algebra, a functor 


Church described three relations on terms. The first relation, alpha, relates any two lambda abstractions that differ only in the variable name. This is exactly the same as when we consider the function 



The really important relation is the second one, “beta reduction”. In order to define beta reduction, we have to define the free variables of a term: a variable occurring by itself is free; the set of free variables in an application is the union of the free variables in its subterms; and the free variables in a lambda abstraction are the free variables of the subterm except for the abstracted variable.

Beta reduction says that when we have a lambda abstraction

where we read the right hand side as “

We say a term has a normal form if there’s some sequence of beta reductions that leads to a term where no beta reduction is possible. When the beta rule applies in more than one place in a term, it doesn’t matter which one you choose to do first: any sequence of betas that leads to a normal form will lead to the same normal form. This property of beta reduction is called confluence. Confluence means that the order of performing various subcomputations doesn’t matter so long as they all finish: in the expression 
“Running” a program in the lambda calculus is the process of computing the normal form by repeated application of beta reduction, and the normal form itself is the result of the computation. Confluence, however, does not mean that when there is more than one place we could apply beta reduction, we can choose any beta reduction and be guaranteed to reach a normal form. The following lambda term, customarily denoted

If we apply 


It’s an infinite loop! Now consider this lambda term that has

It says, “Return the first element of the pair (identity function,
Lazy lambda calculus
Many programming languages, like Java, C, JavaScript, Perl, Python, and Lisp are “eager”: they calculate the normal form of inputs to a function before calculating the result of the function on the inputs; the expression above, implemented in any of these languages, would be an infinite loop. Other languages, like Miranda, Lispkit, Lazy ML, and Haskell and its predecessor Orwell are “lazy” and only apply beta reduction to inputs when they are needed to complete the computation; in these languages, the result is the identity function. Abramsky wrote a 48-page paper about constructing a domain that captures the operational semantics of lazy lambda calculus.
The idea of representing operational semantics directly with higher categories originated with R. A. G. Seely, who suggested that beta reduction should be a 2-morphism; Barney Hilken and Tom Hirschowitz have also contributed to looking at lambda calculus from this perspective. In the “Rosetta stone” paper that John Baez and I wrote, we made an analogy between programs and Feynman diagrams. The analogy is precise as far as it goes, but it’s unsatisfactory in the sense that Feynman diagrams describe processes happening over time, while Lambek and Scott mod out by the process of computation that occurs over time. If we use 2-categories that explicitly model rewrites between terms, we get something that could potentially be interpreted with concepts from physics: types would become analogous to strings, terms would become analogous to space, and rewrites would happen over time.
The idea from the “algebra of terms” perspective is that we have objects
This approach, however, doesn’t work for lazy lambda calculus! Horizontal composition in a 2-category is a functor, so if a term 
In order to model this special context, we reify it: we add a special unary term constructor ![[-]\colon T \to T](https://s0.wp.com/latex.php?latex=%5B-%5D%5Ccolon+T+%5Cto+T&bg=fff&fg=222&s=0&c=20201002)
More concretely, we have two generating rewrite rules. The first propagates the reduction context to the head position in an application; the second is beta reduction restricted to a reduction context.
![\displaystyle [t(t')]\, \downarrow_{ctx}\, [[t](t')]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Bt%28t%27%29%5D%5C%2C+%5Cdownarrow_%7Bctx%7D%5C%2C+%5B%5Bt%5D%28t%27%29%5D&bg=fff&fg=222&s=0&c=20201002)
]\, \downarrow_\beta\, [t]\, \{t'/x\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B%5B%5Clambda+x.t%5D%28t%27%29%5D%5C%2C+%5Cdownarrow_%5Cbeta%5C%2C+%5Bt%5D%5C%2C+%5C%7Bt%27%2Fx%5C%7D&bg=fff&fg=222&s=0&c=20201002)
When we surround the example term from the previous section with a reduction context marker, we get the following sequence of reductions:
![\displaystyle \begin{array}{rl} & [(\lambda x.\lambda y.x)(\lambda x.x)(\Omega)] \\ \downarrow_{ctx}& [[(\lambda x.\lambda y.x)(\lambda x.x)](\Omega)] \\ \downarrow_{ctx}& [[[\lambda x.\lambda y.x](\lambda x.x)](\Omega)] \\ \downarrow_{\beta}& [[\lambda y.(\lambda x.x)](\Omega)]\\ \downarrow_{\beta}& [\lambda x.x] \\ \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cbegin%7Barray%7D%7Brl%7D++%26+%5B%28%5Clambda+x.%5Clambda+y.x%29%28%5Clambda+x.x%29%28%5COmega%29%5D+%5C%5C++++%5Cdownarrow_%7Bctx%7D%26+%5B%5B%28%5Clambda+x.%5Clambda+y.x%29%28%5Clambda+x.x%29%5D%28%5COmega%29%5D+%5C%5C++++%5Cdownarrow_%7Bctx%7D%26+%5B%5B%5B%5Clambda+x.%5Clambda+y.x%5D%28%5Clambda+x.x%29%5D%28%5COmega%29%5D+%5C%5C++++%5Cdownarrow_%7B%5Cbeta%7D%26+%5B%5B%5Clambda+y.%28%5Clambda+x.x%29%5D%28%5COmega%29%5D%5C%5C++++%5Cdownarrow_%7B%5Cbeta%7D%26+%5B%5Clambda+x.x%5D+%5C%5C++%5Cend%7Barray%7D++&bg=fff&fg=222&s=0&c=20201002)
At the start, none of the subterms were of the right shape for beta reduction to apply. The first two reductions propagated the reduction context down to the projection in head position. At that point, the only reduction that could occur was at the application of the projection to the first element of the pair, and after that to the second element. At no point was
Compute resources
In order to run a program that does anything practical, you need a processor, time, memory, and perhaps disk space or a network connection or a display. All of these resources have a cost, and it would be nice to keep track of them. One side-effect of reifying the context is that we can use it as a resource.
The rewrite rule 

![\displaystyle [t(t')]\, \downarrow_{ctx'}\, [t](t')](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Bt%28t%27%29%5D%5C%2C+%5Cdownarrow_%7Bctx%27%7D%5C%2C+%5Bt%5D%28t%27%29++&bg=fff&fg=222&s=0&c=20201002)
then the number of occurences of ![[[\cdots[t]\cdots]]](https://s0.wp.com/latex.php?latex=%5B%5B%5Ccdots%5Bt%5D%5Ccdots%5D%5D&bg=fff&fg=222&s=0&c=20201002)
If we have a nullary constructor 
![[t] = c(t)](https://s0.wp.com/latex.php?latex=%5Bt%5D+%3D+c%28t%29&bg=fff&fg=222&s=0&c=20201002)
In the pi calculus, we have the ability to run multiple processes at the same time; each
These are just the first things that come to mind; we’re experimenting with variations.
Conclusion
We figured out how to model the operational semantics of a term calculus directly in a 2-category by requiring a catalyst to carry out a rewrite, which gave us full abstraction without needing a domain based on representing all the possible futures of a term. As a side-effect, it also gave us a new tool for modeling resource consumption in the process of computation. Though I haven’t explained how yet, there’s a nice connection between the “algebra-of-terms” approach that uses

leave a comment