Category Theory for the Java Programmer
[Edit May 11, 2012: I’ve got a whole blog on Category Theory in JavaScript.]
There are several good introductions to category theory, each written for a different audience. However, I have never seen one aimed at someone trained as a programmer rather than as a computer scientist or as a mathematician. There are programming languages that have been designed with category theory in mind, such as Haskell, OCaml, and others; however, they are not typically taught in undergraduate programming courses. Java, on the other hand, is often used as an introductory language; while it was not designed with category theory in mind, there is a lot of category theory that passes over directly.
I’ll start with a sentence that says exactly what the relation is of category theory to Java programming; however, it’s loaded with category theory jargon, so I’ll need to explain each part.
A collection of Java interfaces is the free3 cartesian4 category2 with equalizers5 on the interface6 objects1 and the built-in7 objects.
1. Objects
Both in Java and in category theory, objects are members of a collection. In Java, it is the collection of values associated to a class. For example, the class Integer may take values from 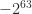

enum Seasons { Spring, Summer, Fall, Winter }
has four possible values.
In category theory, the collection of objects is “half” of a category. The other part of the category is a collection of processes, called “morphisms,” that go between values; morphisms are the possible ways to get from one value to another. The important thing about morphisms is that they can be composed: we can follow a process from an initial value to an intermediate value, and then follow a second process to a final value, and consider the two processes together as a single composite process.
2. Categories
Formally, a category is
- a collection of objects, and
- for each pair of objects
, a set
of morphisms between them
such that
- for each object
the set
contains an identity morphism
- for each triple of objects
and pair of morphisms
and
there is a composite morphism
- for each pair of objects
and morphism
the identitiy morphisms are left and right units for composition:
and
- for each 4-tuple of objects
and triple of morphisms
composition is associative:
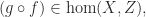

If a morphism 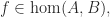
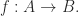
We can also define a category in Java. A category is any implementation of the following interface:
interface Category {
interface Object {}
interface Morphism {}
class IllegalCompositionError extends Error;
Object source(Morphism);
Object target(Morphism);
Morphism identity(Object);
Morphism compose(Morphism, Morphism)
throws IllegalCompositionError;
};
that passes the following tests on all inputs:
void testComposition(Morphism g, Morphism f) {
if (target(f) != source(g)) {
assertRaises(compose(g, f),
IllegalCompositionError);
} else {
assertEqual(source(compose(g, f)), source(f));
assertEqual(target(compose(g, f)), target(g));
}
}
void testAssociativity(Morphism h,
Morphism g,
Morphism f) {
assertEqual(compose(h, compose(g, f)),
compose(compose(h, g), f));
}
void testIdentity(Object x) {
assertEqual(source(identity(x)), x);
assertEqual(target(identity(x)), x);
}
void testUnits(Morphism f) {
assertEqual(f, compose(identity(target(f)), f));
assertEqual(f, compose(f, identity(source(f))));
}
One kind of category that programmers use every day is a monoid. Monoids are sets equipped with a multiplication table that’s associative and has left- and right units. Monoids include everything that’s typically called addition, multiplication, or concatenation. Adding integers, multiplying matrices, concatenating strings, and composing functions from a set to itself are all examples of monoids.
In the language of category theory, a monoid is a one-object category (monos is Greek for “one”). The set of elements you can “multiply” is the set of morphisms from that object to itself.
In Java, a monoid is any implementation of the Category interface that also passes this test on all inputs:
void testOneObject(Morphism f, Object x) {
assertEqual(source(f), x);
}
The testOneObject test says that given any morphism f and any object x, the source of the morphism has to be that object: given another object y, the test says that source(f) == x and source(f) == y, so x == y. Therefore, if the category passes this test, it has only one object.
For example, consider the monoid of XORing bits together, also known as addition modulo 2. Adding zero is the identity morphism for the unique object; we need a different morphism to add 1:
interface Parity implements Category {
Morphism PlusOne();
}
The existence of the PlusOne method says that there has to be a distinguished morphism, which could potentially be different from the identity morphism. The interface itself can’t say how that morphism should behave, however. We need tests for that. The testPlusOne test says that (1 + 1) % 2 == 0. The testOneIsNotZero test makes sure that we don’t just set 1 == 0: since (0 + 0) % 2 == 0, the first test isn’t enough to catch this case.
void testOnePlusOne(Object x) {
assertEqual(compose(PlusOne(), PlusOne()),
identity(x));
}
void testOneIsNotZero(Object x) {
assertNotEqual(PlusOne(), identity(x));
}
Here’s one implementation of the Parity interface that passes all of the tests for Category, testOneObject, and the two Parity tests:
class ParityImpl implements Parity {
enum ObjectImpl implements Object { N };
enum MorphismImpl implements Morphism {
PlusZero,
PlusOne
};
Object source(Morphism) { return N; }
Object target(Morphism) { return N; }
Morphism identity(Object) { return PlusZero; }
Morphism compose(Morphism f, Morphism g) {
if (f == PlusZero) return g; // 0 + g = g
if (g == PlusZero) return f; // f + 0 = f
return PlusZero; // 1 + 1 = 0
}
Morphism PlusOne() { return PlusOne; }
}
3. Free
Java tests are a kind of “blacklisting” approach to governing implementations. Had we not added testOneIsNotZero, we could have returned PlusZero and the compiler would have been happy. In a free category, relations are “whitelisted:” an implementation must not have relations (constraints) other than the ones that are implied by the definitions.
- “The free category” has no objects and no morphisms, because there aren’t any specified.
- “The free category on one object
” has one object and one morphism, the identity
The morphism has to be there, because the definition of category says that every object has to have an identity morphism, but we can’t put in any other morphisms.
- “The free category on the directed graph
”
A -f-> B | / G = h g | / V L Chas
- three objects
and
- seven morphisms:
,
,
,
,
,
, and
.
The three vertices and the three edges become objects and morphisms, respectively. The three identity morphisms and
are required to be there because of the definition of a category. And because the category is free, we know that
For abritrary directed graphs, the free category on the graph has the vertices of the graph as objects and the paths in the graph as morphisms.
- three objects
- The parity monoid is completely defined by “the free category on one object
and one relation
“
- If we leave out the relation and consider “the free category on one object
we form
- Exercise: what is the common name for “the free category on one object
?” What should the identity morphism be named?

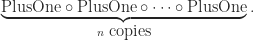
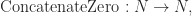
4. Cartesian
A cartesian category has lists as its objects. It has a way to put objects together into ordered pairs, a way to copy objects, and an object that’s “the empty” object.
It’s time to do the magic! Recall the interface Category:
interface Category {
interface Object {}
interface Morphism {}
class IllegalCompositionError extends Error;
Object source(Morphism);
Object target(Morphism);
Morphism identity(Object);
Morphism compose(Morphism, Morphism)
throws IllegalCompositionError;
};
Now let’s change some names:
interface Interface {
interface InternalInterfaceList {}
interface ComposableMethodList {}
class IllegalCompositionError extends Error;
InternalInterfaceList source(ComposableMethodList);
InternalInterfaceList target(ComposableMethodList);
ComposableMethodList identity(InternalInterfaceList);
ComposableMethodList compose(ComposableMethodList,
ComposableMethodList)
throws IllegalCompositionError;
}
Category theory uses cartesian categories to describe structure; Java uses interfaces. Whenever you see “cartesian category,” you can think “interface.” They’re pretty much the same thing. Practically, that means that a lot of the drudgery of implementing the Category interface is taken care of by the Java compiler.
For example, recall the directed graph
interface G {
interface A;
interface B;
interface C;
B f(A);
C g(B);
C h(A);
}
That’s it! We’re considering the free category on 
Because the objects of the cartesian category Interface are lists, we can define methods in our interfaces that have multiple inputs.
interface Monoid {
interface M;
M x(M, M);
M e();
}
void testX(M a, M b, Mc) {
assertEqual(x(a, x(b, c)),
x(x(a, b), c));
}
void testE(M a) {
assertEqual(a, x(a, e()));
assertEqual(a, x(e(), a));
}
Here, the method x takes a two-element list as input, while e takes an empty list.
Exercise: figure out how this definition of a monoid relates to the one I gave earlier.
Implementation as a functor
Cartesian categories (interfaces) provide the syntax for defining data structures. The meaning, or semantics, of Java syntax comes from implementing an interface.
In category theory, functors give meaning to syntax. Functors go between categories like functions go between sets. A functor
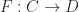
- maps objects of
to objects of
and
- maps morphisms of
- identities and composition are preserved.
There are several layers of functors involved in implementing a typical Java program. First there’s the implementation of the interface in Java as a class that defines everything in terms of the built-in classes and their methods; next, there’s the implementation of the built-in methods in the Java VM, then implementation of the bytecodes as native code on the machine, and finally, physical implementation of the machine in silicon and electrons. The composite of all these functors is supposed to behave like a single functor into 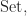
The upshot of all this is that a Java class F implementing an interface X can be thought of as a functor 
Here’s an example of three different classes that implement the Monoid interface from the last subsection. Recall that a monoid is a set of things that we can combine; we can add two integers to get an integer, multiply two doubles to get a double, or concatenate two strings to get a string. The combining operation is associative and there’s a special element that has no effect when you combine it with something else: adding zero, multiplying by 1.0, or concatenating the empty string all do nothing.
So, for example,
class AddBits implements Monoid {
enum Bit implements M { Zero, One }
M x(M f, M g) {
if (f == e()) return g; // 0+g=g
if (g == e()) return f; // f+0=f
return Zero; // 1+1=0
}
M e() { return Zero; }
}
Here, the functor 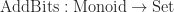
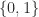

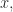
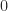
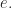
class MultiplyBits implements Monoid {
enum Bit implements M { Zero, One }
M x(M f, M g) {
if (f == e()) return g; // 1*g=g
if (g == e()) return f; // f*1=f
return Zero; // 0*0=0
}
M e() { return One; }
}
Here, the functor 
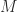


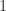
class Concatenate implements Monoid {
class ConcatString implements M {
ConcatString(String x) {
this.x = x;
}
String x;
}
M x(M f, M g) {
return new ConcatString(
f.x + g.x);
}
M e() {
return new ConcatString("");
}
}
Here, the functor 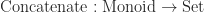
5. Equalizers
An equalizer of two functions 
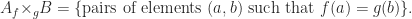
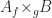
In Java, this means that we can throw an exception if the pair isn’t composable.
6, 7. Interface objects and built-in objects
The objects of the free category in question are java interfaces, whether defined by the programmer or built-in. Because it’s cartesian, we can combine interfaces into new interfaces:
interface XYPair { interface X; interface Y; }
The built-in objects have some relations between them–we can cast an integer into a double, for instance, or turn an integer into a string–so these relations exist between combinations of arbitrary interfaces with built-in ones. But there are no automatic cast relationships between user-defined interfaces, so the category is free.
Next time
This post was about how to translate between Java ideas and category-theory ideas. Next time, I’ll show what category theory has to offer to the Java programmer.

13 comments