Semantics for the blue calculus
| Blue calculus | MonCat |  |
2Hilb | Set (as a one object bicategory) |
| Types | monoidal categories | manifolds | 2 Hilbert spaces | * |
| Terms with one free variable | monoidal functors | manifolds with boundary | linear functors | sets |
| Rewrite rules | monoidal natural transformation | manifolds with corners | linear natural transformations | functions |
| Tensor product |  |
juxtaposition (disjoint union) | tensor product | cartesian product |
 where where  is free is free |
![([[T]] \otimes_Y [[T']]):X \to Y](https://s0.wp.com/latex.php?latex=%28%5B%5BT%5D%5D+%5Cotimes_Y+%5B%5BT%27%5D%5D%29%3AX+%5Cto+Y&bg=fff&fg=222&s=0&c=20201002) |
formal sum of cobordisms with boundary from 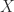 to to  |
sum of linear functors | disjoint union |
In the MonCat column,
The Sum of Forking Paths
Paracelsus threw the rose into the fire; it bent on impact, recoiled, and fell deeper among the logs. In the gold-orange light, the stem was already black. The husk began to shrivel and split as the sap boiled away on its surface. The petals blistered and blackened and fell. The five-fingered star beneath them danced subtly, swaying in the brittle heat. For nearly an hour it lay visibly unchanged save for a gradual loss of hue and a universal greyness, then fell into three large pieces as the log crumbled around it. The ashes glowed orange, then gradually dimmed; the last visible flash of light burst outward from the remains of the stem. Like all light, it carried within it a timepiece.
Once, when the clock read noon, it traveled without hesitation in a straight path to my retina. Once it took another course, only to bend around a molecule of nitrogen and reach the same destination.
Once it traced the signature of a man no one remembers.
Once, at half past three, it decayed into a tiny spark and its abominable opposite image; their mutual horrified fascination drew them together, each a moth in the other’s flame. The last visible flash of light from their fiery consummation was indistinguishable from the one that spawned them.
Once, when the clock ticked in the silence just before dawn, the light decayed into two mirrored worlds, somewhat better than ours due to the fact that I was never born there. Both worlds were consumed by mirrored dragons before collapsing back into the chaos from which they arose; all that remained was an orange flash of light.
Once it traveled to a far distant galaxy, reflected off the waters of a billion worlds and witnessed the death of a thousand stars before returning to the small room in which we sat.
Once it transcribed a short story of Borges in his own cramped scrawl, the six versions he discarded, the corrupt Russian translation by Nabokov, and a version in which the second-to-last word was illegible.
Once it traveled every path, each in its time; once it became and destroyed every possible world. All these summed to form what was: I saw an orange flash, and in that moment, I was enlightened.
An analogy
| Stat mech | Quant mech | |
| column vector | distribution |
amplitude distribution (wave function) |
| row vector | population , ,where  are the coefficients that, when normalized, maximize the inner product with are the coefficients that, when normalized, maximize the inner product with  |
 , ,where  is the complex conjugate of is the complex conjugate of  . . |
| normalization |  |
 |
| transitions | stochastic | unitary |
| harmonic oscillator | many HOs at temperature  |
one QHO evolving for time 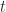 |
uniform distribution over 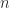 states states |
 |
 |
| special distribution | Gibbs distribution  |
Free evolution  |
partition function = inner product with  |
 |
 |
 |
 |
 |
| path integrals |  = maximum entropy? = maximum entropy? |
 = least action? = least action? |
Simple activity for teaching about radiometric dating
This works best with small groups of about 5-10 students and at least thirty dice. Divide the dice evenly among the students.
- Count the number of dice held by the students and write it on the board.
- Have everyone roll each die once.
- Collect all the dice that show a ‘one’, count them, write the sum on the board, then set them aside.
- Go back to step 1.
A run with 30 dice will look something like this:
| dice | number of ones |
| 30 | 5 |
| 25 | 4 |
| 21 | 4 |
| 17 | 3 |
| 14 | 1 |
| 13 | 3 |
| 10 | 2 |
| 8 | 1 |
| 7 | 1 |
| 6 | 0 |
| 6 | 1 |
| 5 | 0 |
| 5 | 1 |
| 4 | 1 |
| 3 | 0 |
| 3 | 0 |
| 3 | 0 |
| 3 | 1 |
| 2 | 1 |
| 1 | 0 |
| 1 | 0 |
| 1 | 0 |
| 1 | 0 |
| 1 | 1 |
Point out how the number of dice rolling a one on each turn is about one sixth of the dice that hadn’t yet rolled a one on the previous turn. Also, that you lose about half of the remaining dice after about four turns.
Send someone out of the room; do either four or eight turns, then bring them back and ask them to guess how many turns the group took. The student should be able to see that if half the dice are left, there were only four turns, but if a quarter of the dice are left, there were eight turns.
If the students are advanced enough to use logarithms, try the above with some number other than four or eight and have the student use logarithms to calculate the number of turns:
turns = log(number remaining/total) / log(5/6),
or, equivalently, in terms of the half-life (which is really closer to 3.8 than 4):
turns = 3.8 * log(number remaining/total) / log(1/2).
When Zircon crystals form, they strongly reject lead atoms: new zircon crystals have no lead in them. They easily accept uranium atoms. Each die represents a uranium atom, and rolling a one represents decaying into a lead atom: because uranium atoms are radioactive, they can lose bits of their nucleus and turn into lead–but only randomly, like rolling a die. Instead of four turns, the half-life of U238 is 4.5 billion years.
Zircon forms in almost all rocks and is hard to break down. So to judge the age of a rock, you get the zircon out, throw it in a mass spectrometer, look at the proportion of uranium to (lead plus uranium) and calculate
years = 4.5 billion * log(mass of uranium/mass of (lead+uranium)) / log(1/2).
Problem: given a zircon crystal where there’s one lead atom for every ninety-nine uranium atoms, how long ago was it formed?
4.5 billion * log(99/100) / log(1/2) = 65 million years ago.
In reality, it’s slightly more complicated: there are two isotopes of uranium and several of lead. But this is a good thing, since we know the half-lives of both isotopes and can use them to cross-check each other; it’s as though each student had both six- and twenty-sided dice, and the student guessing the number of turns could use information from both groups to refine her guess.
Lazulinos
Lazulinos are quasiparticles in a naturally occurring Bose-Einstein condensate first described in 1977 by the Scottish physicist Alexander Craigie while at the University of Lahore [3]. The quasiparticles are weakly bound by an interaction for which neither the position nor number operator commutes with the Hamiltonian. A measurement of a lazulino’s position will cause the condensate to go into a superposition of number states, and a subsequent measurement of the population will return a random number; also, counting the lazulinos at two different times will likely give different results.
Their name derives from the stone lapis lazuli and means, roughly, “little blue stone”. Lazulinos are so named because even though the crystals in which they arise absorb visible light, and would otherwise be jet black, they lose energy through surface plasmons in the form of near-ultraviolet photons, with visible peaks at 380, 402, and 417nm. Optical interference imparts a “laser speckle” quality to the emitted light; Craigie described the effect in a famously poetic way: “Their colour is the blue that we are permitted to see only in our dreams”. What makes lazulinos particularly interesting is that they are massive and macroscopic. Since the number operator does not commute with the Hamiltonian, lazulinos themselves do not have a well-defined mass; if the population is N, then the mass of any particular lazulino is m/N, where m is the total mass of the condensate.
In a recent follow-up to the “quantum mirage” experiment [2], Don Eigler’s group at IBM used a scanning tunneling microscope to implement “quantum mancala”—picking up the lazulino ‘stones’ in a particular location usually changes the number of stones, so the strategy for winning becomes much more complicated. In order to pick up a fixed number of stones, you must choose a superposition of locations [1].
- C.P. Lutz and D.M. Eigler, “Quantum Mancala: Manipulating Lazulino Condensates,” Nature 465, 132 (2010).
- H.C. Manoharan, C.P. Lutz and D.M. Eigler, “Quantum Mirages: The Coherent Projection of Electronic Structure,” Nature 403, 512 (2000). Images available at http://www.almaden.ibm.com/almaden/media/image_mirage.html
- A. Craigie, “Surface plasmons in cobalt-doped Y3Al5O12,” Phys. Rev. D 15 (1977). Also available at http://tinyurl.com/35oyrnd.
Coends
Coends are a categorified version of “summing over repeated indices”. We do that when we’re computing the trace of a matrix and when we’re multiplying two matrices. It’s categorified because we’re summing over a bunch of sets instead of a bunch of numbers.
Let 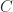

- to each pair of objects the set of morphisms between them, and
- to each pair of morphisms
a function that takes a morphism
and returns the composite morphism
, where

It turns out that given any functor 
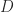

- to each pair of objects a set of morphisms between them, and
- to each pair of morphisms
and returns the composite morphism
, where
and

We can think of these functors as adjacency matrices, where the two parameters are the row and column, except that instead of counting the number of paths, we’re taking the set of paths. So
The coend of

The top set consists of all the pairs where
- the first element is a morphism
and
- the second element is a morphism

The bottom set is the set of all the endomorphisms in
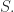
The coequalizer of the diagram, the coend of 


where I’m using the lollipop to mean a morphism from
So this says take all the endomorphisms that can be chopped up into a morphism 


To get the trace of the hom functor, use 
The coend is also used when “multiplying matrices”. Let 



That is, it doesn’t matter if you think of 
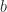

Notice here how a morphism can turn “inside out”: when 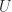
Renormalization and Computation 4
This is the fourth in a series of posts on Yuri Manin’s pair of papers. In the previous posts, I laid out the background; this time I’ll actually get around to his result.
A homomorphism from the Hopf algebra into a target algebra is called a character. The functor that assigns an action to a path, whether classical or quantum, is a character. In the classical case, it’s into the rig 

Manin mentions that the runtime of a parallel program is a character akin to the classical action, with the runtime of the composition of two programs being the sum of the respective runtimes, while the runtime of two parallel programs is the maximum of the two. A similar result holds for nearly any cost function. He also points out that computably enumerable reals 

In the second paper, he looks at my work with Calude as an example of a character. He uses our same argument to show that lots of measures of program behavior have the property that if the measure hasn’t stopped growing after reaching a certain large amount with respect to the program size, then the density of finite values the measure could take decreases like 
Reading between the lines, he might be suggesting something like approximating the Kolmogorov complexity that he uses later by using a time cutoff, motivated by results from our paper: there’s a constant 


Levin suggested using a computable complexity that’s the sum of the program length and the log of the number of time steps; I suppose you could “regularize” the Kolmogorov complexity by adding 

Instead, he proposed two other constructions suitable for renormalization; here’s the simplest. Given a partial computable function 




When 




The other construction involves turning 

So Manin’s idea of renormalizing the halting problem is to do some uncomputable stuff to get an easy-to-renormalize function and then throw the Birkhoff decomposition at it; since we know the halting problem is undecidable, perhaps the fact that he didn’t come up with a new technique for extracting information about the problem is unsurprising, but after putting in so much effort to understand it, I was left rather disappointed: if you’re going to allow yourself to do uncomputable things, why not just solve the halting problem directly?
I must suppose that his intent was not to tackle this hard problem, but simply to play with the analogy he’d noticed; it’s what I’ve done in other papers. And being forced to learn renormalization was exhilarating! I have a bunch of ideas to follow up; I’ll write them up as I get a chance.
Renormalization and Computation 2
This is the second in a series of posts covering Yuri Manin’s ideas involving Hopf algebra renormalization of the Halting problem. Last time I showed how perturbing a quantum harmonic oscillator gave a sum over integrals involving
One point about the QHO needs emphasis at this point. Given a wavefunction 

This is called the normalization condition.
When we perturb the QHO, the states 


where 

Since we’re working with a new set of coefficients, we have to make sure they sum up to unity, too:

This is the renormalization condition. So renormalization is about making sure things sum up right once you perturb the system.
I want to talk about renormalization in quantum field theory; the trouble is, I don’t actually know quantum field theory, so I’ll just be writing up what little I’ve gathered from reading various things and conversations with Dr. Baez. I’ve likely got some things wrong, so please let me know and I’ll fix them.
A field is a function defined on spacetime. Scalar fields are functions with a single output, whereas vector fields are functions with several outputs. The electromagnetic field assigns a single number, called the electric field, and a vector, called the magnetic field, to every point in spacetime. When you have two electrons and move one of them, it feels a reaction force and loses momentum; the other electron doesn’t move until the influence, traveling at the speed of light, reaches it. Conservation of momentum says that the momentum has to be somewhere; it’s useful to consider it to be in the electromagnetic field.
When you take the Fourier transform of the field, you get a function that assigns values to harmonics of the field; in the case of electromagnetism, the transformed field 




When we move to positive-dimensional fields, we get more interesting pictures, like these from quantum electrodynamics:

Here, our coupling constant is the fine structure constant 



The trouble is, this integral usually gives infinity for an answer. We try to work around this in two steps: first, we regularize the integral by introducing a length scale 
There are a few different ways of regularizing; one is to use

This obviously converges, and solutions to this are always a sum of three parts:
- The first part diverges as
either logarithmically or as a power of
- The second part is finite and independent of
- The third part vanishes as
Renormalization in this case amounts to getting rid of the first part.
These three parts represent three different length scales: at lengths larger than 

The problem with this regularization scheme is that it doesn’t preserve gauge invariance, so usually physicists use another regularization scheme, called “dimensional regularization”. Here, we compute

which gives us an expression involving gamma functions of 
Assume we have some theory with a single free parameter 



and assume that this definition gives us divergent integrals for the 

Now we get to the business of renormalization! We solve this problem at each order; if the theory is renormalizable, knowing the solution at the previous order will give us a constraint for the next order, and we can subtract off all the divergent terms in a consistent way:
- Order
Here,
Since it’s a constant, it has to match
so
In this approximation, the coupling constant takes the classical value.
- Order
Let
where
Plugging this into the definition of
we get
Using
which diverges as
In the case of QED, this says that the charge on the electron is infinite. While the preferred interpretation these days is that quantum gravity is a more fundamental theory that takes precedence on very small scales (a Planck length is to a proton as a proton is to a meter), when the theory was first introduced, there was no reason to think that we’d need another theory. So the interpretation was that with an infinite charge, an electron would be able to extract an infinite amount of energy from the electromagnetic field. Then the uncertainty principle would create virtual particles of all energies, which would exist for a time inversely proportional to the energy. The particles can be charged, so they line up with the field and dampen the strength just like dielectrics. In this interpretation, the charge on the electron depends on the energy of the particles you’re probing it with.
So to second order,
A theory is therefore only renormalizable if the divergent part of
is independent of
In QED it is. We can now define
- Higher orders.
In a renormalizable theory, the process continues, with the counterterms entirely specified by knowing






Renormalization and Computation 1
Yuri Manin recently put two papers on the arxiv applying the methods of renormalization to computation and the Halting problem. Grigori Mints invited me to speak on Manin’s results at the weekly Stanford logic seminar because in his second paper, he expands on some of my work.
In these next few posts, I’m going to cover the idea of Feynman diagrams (mostly taken from the lecture notes for the spring 2004 session of John Baez’s Quantum Gravity seminar); next I’ll talk about renormalization (mostly taken from Andrew Blechman’s overview and B. Delamotte’s “hint”); third, I’ll look at the Hopf algebra approach to renormalization (mostly taken from this post by Urs Schreiber on the n-Category Café); and finally I’ll explain how Manin applies this to computation by exploiting the fact that Feynman diagrams and lambda calculus are both examples of symmetric monoidal closed categories (which John Baez and I tried to make easy to understand in our Rosetta stone paper), together with some results on the density of halting times from my paper “Most programs stop quickly or never halt” with Cris Calude. I doubt all of this will make it into the talk, but writing it up will make it clearer for me.
Renormalization is a technique for dealing with the divergent integrals that arise in quantum field theory. The quantum harmonic oscillator is quantum field theory in 0+1 dimensions—it describes what quantum field theory would be like if space consisted of a single point. It doesn’t need renormalization, but I’m going to talk about it first because it introduces the notion of a Feynman diagram.
“Harmonic oscillator” is a fancy name for a rock on a spring. The force exerted by a spring is proportional to how far you stretch it:

The potential energy stored in a stretched spring is the integral of that:

and to make things work out nicely, we’re going to choose 


By choosing units so that 

where 
Next we quantize, getting a quantum harmonic oscillator, or QHO. We set 

![\begin{array}{rl}\displaystyle [x, p]x^n & \displaystyle = xp - px \\ & = (- x i \frac{\partial}{\partial x} + i \frac{\partial}{\partial x} x)x^n \\\ & \displaystyle = -i(nx^n - (n+1)x^n) \\ & \displaystyle = ix^n.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7D%5Cdisplaystyle+%5Bx%2C+p%5Dx%5En+%26+%5Cdisplaystyle+%3D+xp+-+px+%5C%5C+%26+%3D+%28-+x+i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D+%2B+i+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D+x%29x%5En+%5C%5C%5C+%26+%5Cdisplaystyle+%3D+-i%28nx%5En+-+%28n%2B1%29x%5En%29+%5C%5C+%26+%5Cdisplaystyle+%3D+ix%5En.%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
If we define a new observable 

We can think of 



The creation operator 


Schrödinger’s equation says 

This way of representing the state of a QHO is known as the “Fock basis”.
Now suppose that we don’t have the ideal system, that the quadratic potential 




Now we solve Schrödinger’s equation perturbatively. We know that

and we assume that

so that it makes sense to solve it perturbatively. Define

and

After a little work, we find that

and integrating, we get

We feed this equation back into itself recursively to get
![\begin{array}{rl}\displaystyle \psi_1(t) & \displaystyle = -i \int_0^t V_1(t_0) \left[-i\int_0^{t_0} V_1(t_1) \psi_1(t_1) dt_1 + \psi(0) \right] dt_0 + \psi(0) \\ & \displaystyle = \left[\psi(0)\right] + \left[\int_0^t i^{-1} V_1(t_0)\psi(0) dt_0\right] + \left[\int_0^t\int_0^{t_0} i^{-2} V_1(t_0)V_1(t_1) \psi_1(t_1) dt_1 dt_0\right] \\ & \displaystyle = \sum_{n=0}^{\infty} \int_{t \ge t_0 \ge \ldots \ge t_{n-1} \ge 0} i^{-n} V_1(t_0)\cdots V_1(t_{n-1}) \psi(0) dt_{n-1}\cdots dt_0 \\ & \displaystyle = \sum_{n=0}^{\infty} (-\lambda i)^n \int_{t \ge t_0 \ge \ldots \ge t_{n-1} \ge 0} e^{-i(t-t_0)H_0} V e^{-i(t_0-t_1)H_0} V \cdots V e^{-i(t_{n-1}-0)H_0} \psi(0) dt_{n-1}\cdots dt_0.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brl%7D%5Cdisplaystyle+%5Cpsi_1%28t%29+%26+%5Cdisplaystyle+%3D+-i+%5Cint_0%5Et+V_1%28t_0%29+%5Cleft%5B-i%5Cint_0%5E%7Bt_0%7D+V_1%28t_1%29+%5Cpsi_1%28t_1%29+dt_1+%2B+%5Cpsi%280%29+%5Cright%5D+dt_0+%2B+%5Cpsi%280%29+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Cleft%5B%5Cpsi%280%29%5Cright%5D+%2B+%5Cleft%5B%5Cint_0%5Et+i%5E%7B-1%7D+V_1%28t_0%29%5Cpsi%280%29+dt_0%5Cright%5D+%2B+%5Cleft%5B%5Cint_0%5Et%5Cint_0%5E%7Bt_0%7D+i%5E%7B-2%7D+V_1%28t_0%29V_1%28t_1%29+%5Cpsi_1%28t_1%29+dt_1+dt_0%5Cright%5D+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Csum_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+%5Cint_%7Bt+%5Cge+t_0+%5Cge+%5Cldots+%5Cge+t_%7Bn-1%7D+%5Cge+0%7D+i%5E%7B-n%7D+V_1%28t_0%29%5Ccdots+V_1%28t_%7Bn-1%7D%29+%5Cpsi%280%29+dt_%7Bn-1%7D%5Ccdots+dt_0+%5C%5C+%26+%5Cdisplaystyle+%3D+%5Csum_%7Bn%3D0%7D%5E%7B%5Cinfty%7D+%28-%5Clambda+i%29%5En+%5Cint_%7Bt+%5Cge+t_0+%5Cge+%5Cldots+%5Cge+t_%7Bn-1%7D+%5Cge+0%7D+e%5E%7B-i%28t-t_0%29H_0%7D+V+e%5E%7B-i%28t_0-t_1%29H_0%7D+V+%5Ccdots+V+e%5E%7B-i%28t_%7Bn-1%7D-0%29H_0%7D+%5Cpsi%280%29+dt_%7Bn-1%7D%5Ccdots+dt_0.%5Cend%7Barray%7D&bg=fff&fg=222&s=0&c=20201002)
So here we have a sum of a bunch of terms; the
Here’s an example Feynman diagram for this simple system, representing the fourth term in the sum above:

The lines represent evolving under the free Hamiltonian
As an example, let’s consider 




A particle moving in a quadratic potential in
The vertices are interactions with the electromagnetic field. The straight lines are electrons and the wiggly ones are photons; between interactions, they propagate under the free Hamiltonian.
My talk at Perimeter Institute
I spent last week at the Perimeter Institute, a Canadian institute founded by Mike Lazaridis (CEO of RIM, maker of the BlackBerry) that sponsors research in cosmology, particle physics, quantum foundations, quantum gravity, quantum information theory, and superstring theory. The conference, Categories, Quanta, Concepts, was organized by Bob Coecke and Andreas Döring. There were lots of great talks, all of which can be found online, and lots of good discussion and presentations, which unfortunately can’t. (But see Jeff Morton’s comments.) My talk was on the Rosetta Stone paper I co-authored with Dr. Baez.
The partition function and Wick rotation
I was trying to understand Wick rotation by applying it in the case of a finite-dimensional Hilbert space, and came up with something strange. The way I’ve worked it out, it seems to map classical observables to quantum states! I’ve never heard anything like that before.
Say we have an 






where the 
Now define the operators

and 


where the normalizing factor 
- What’s the probability amplitude that when you start in the state
and evolve according to
, the system will still be in the state



Except for a factor of 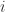
- What’s the probability amplitude that when you start in the state
Well,
where each
is a normalizing factor. So



If we divide this by the quantity above, we get the expectation value of a classical observable 


This mapping from classical to quantum is not quantization. That maps classical observables to Hermetian operators, not to states—although, one might hit the state with the “Currying” isomorphism between states and linear transformations and get something useful.
I’m trying to work out how to connect this to a sum over paths instead of a sum over states; there’s some interesting stuff there, but I haven’t grokked it yet.
MILL, BMCCs, and dinatural transformations
I’m looking at multiplicative intuitionistic linear logic (MILL) right now and figuring out how it’s related to braided monoidal closed categories (BMCCs).
The top and bottom lines in the inference rules of MILL are functors that you get from the definition of BMCCs, so they exist in every BMCC. Given a braided monoidal category C, the turnstile symbol

is the external hom functor (that is, 


Let 

can be seen as a functor from the category (
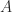



For every morphism 



that maps to a commuting square in


In other words, it assigns to each object x in C a morphism α_x in D such that the square above commutes.
Now consider the case where we want a natural transformation α between two functors
op F,G: C × C -> D.
Given f:x->y, g:s->t, we get a commuting cube in (A × C^op × C) that maps to a commuting cube in D.
G(1_t,f)
Gtx -------------------> Gty
7| 7|
/ | / |
α_tx / |G(g,1_x) α_ty / |
/ | / | G(g,1_y)
/ | / |
/ V G(1_s,f) / V
/ Gsx -------------- /---> Gsy
/ 7 / 7
/ / / /
/ / / /
/ / F(1_t,f) / / α_sy
Ftx -------------------> Fty /
| / | /
| / | /
F(g,1_x) | / α_sx | F(g,1_y)
| / | /
| / | /
V/ F(1_s,f) V/
Fsx -------------------> Fsy
This is bigger, but still straightforward.
To get a dinatural transformation, we set g:=f and then choose a specific route around the cube so that both of the indices are the same on α.
....................... Gyy
.. 7|
. . / |
. . α_yy / |
. . / | G(f,1_y)
. . / |
. . G(1_x,f) / V
. Gxx -------------- /---> Gxy
. 7 / .
. / / .
. / / .
. / F(1_y,f) / .
Fyx -------------------> Fyy .
| / . .
| / . .
F(f,1_x) | / α_xx . .
| / . .
| / . .
V/ ..
Fxx .......................
In other words, a dinatural transformation α: F -> G assigns to each object x a morphism α_xx such that the diagram above commutes.
Dinatural transformations come up when you’re considering two of MILL’s inference rules, namely
x ⊢ y y ⊢ z
------- (Identity) and --------------- (Cut)
x ⊢ x x ⊢ z
These two have the same symbol appearing on both sides of the turnstile, x in the Identity rule and y in the Cut rule. Setting
Fxy = * ∈ Set,
where * is the one-element set, and
Gxy = x ⊢ y ∈ Set,
the Identity rule specifies that given f:x->y we have that f o 1_x = 1_y o f:
.......................y ⊢ y
.. 7|
. . / |
. . α_yy / |
. . / | 1_y o f
. . / |
. . f o 1_x / V
. x ⊢ x ------------- /--> x ⊢ y
. 7 / .
. / / .
. / / .
. / 1 / .
* ---------------------> * .
| / . .
| / . .
1 | / α_xx . .
| / . .
| / . .
V/ ..
* ........................
where
α_xx:* -> x ⊢ x * |-> 1_x
picks out the identity morphism on x.
In the Cut rule, we let j:x->s, k:t->z, and f:s->t,
F(t,s) = (x ⊢ s, t ⊢ z)
j f k
F(1,f) = (x ---> s ---> t, t ---> z)
j f k
F(f,1) = (x ---> s, s ---> t ---> z)
G(s,t) = x ⊢ z
and consider the diagram for a morphism f:s->t in C.
.......................x ⊢ z
.. 7|
. . / |
. . composition / |
. . / | 1
. . / |
. . 1 / V
. x ⊢ z ------------- /--> x ⊢ z
. 7 / .
. / / .
. / / .
. / F(f,1) / .
(x ⊢ s, t ⊢ z) -------> (x ⊢ s, s ⊢ z)
| / . .
| / . .
| / composition . .
F(1,f) | / . .
| / . .
V/ ..
(x ⊢ t, t ⊢ z) .................
which says that composition of morphisms is associative.
Dequantization and deformation
A rig is a ring without negatives, like the nonnegative integers. You can add and multiply them, multiplication distributes over addition, and you’ve got additive and multiplicative identities 0 and 1.
There’s another rig, called the “rig of costs,” that everyone uses when planning a trip: given two alternative plane tickets from A to B, we chose the least expensive one. We add the cost of a trip from A to B with the cost of a trip from B to C. This one’s denoted

Notice that “addition” here is min, and the additive identity is 


As described here, one can deform the rig

to the rig

where

like this:

As 

In quantum mechanics, the path a particle takes is governed by integrating the amplitude, so the probability amplitude of arriving at point

In classical mechanics, the path a particle takes is governed by the principle of least action, so the action cost of arriving at point

where “inf” means “infimum,” i.e. the least element of an infinite set. You get from the complex numbers to the rig 

and classical mechanics falls out of quantum mechanics as 
No one’s heard of the latter one, but you can describe a classical system with a wavefunction! Instead of the probability amplitude at a given point, it’s the action cost.
Week 241
LIGO, the Fool’s Golden Ratio and Stonehenge’s Platonic solids 1600 years before Plato.
http://math.ucr.edu/home/baez/week241.html
Quantum lambda calculus, symmetric monoidal closed categories, and TQFTs
The last post was all about stuff that’s already known. I’ll be working in my thesis on describing the syntax of what I’ll call simply-typed quantum lambda calculus. Symmetric monoidal closed categories (SMCCs) are a generalization of CCCs; they have tensor products instead of products. One of the immediate effects is the lack of built-in projection morphisms 

The typical CCC in which models of a lambda theory are interpreted is Set. The typical SMCC in which models of a quantum lambda theory will be interpreted is Hilb, the category of Hilbert spaces and linear transformations between them. Models of lambda theories correspond to functors from the CCC arising from the theory into Set. Similarly, models of a quantum lambda theory should be functors from a SMCC to Hilb.
Two-dimensional topological quantum field theories (TQFTs) are close to being a model of a quantum lambda theory, but not quite.
There’s a simpler syntax than the simply-typed lambda calculus, called universal algebra, in which one writes algebraic theories. These give rise to categories with finite products (no exponentials) , and functors from these categories to Set pick out sets with the given structure. There’s an algebraic theory of groups, and the functors pick out sets with functions that behave like unit, inverse, and multiplication. So our “programs” consist solely of operations on our data type.
TQFTs are functors from 2Cob, the theory of a commutative Frobenius algebra, to Hilb. We can look at 2Cob as defining a data type and a TQFT as a quantum implementation of the type. When we take the free SMCC over 2Cob, we ought to get a full-fledged quantum programming language with a commutative Frobenius algebra data type. A TQFT would be part of the implementation of the language.
CCCs and lambda calculus
I finally got it through my thick skull what the connection is between lambda theories and cartesian closed categories.
The lambda theory of a set has a single type, with no extra terms or axioms. This gives rise to a CCC where the objects are generated by products and exponentials of a distinguished object, the free CCC on one object. For example, from a type 






The functor itself, however, can be uncomputable: one could, for example, have
When we have types and axioms involved, then we add structure to the set, constraints that the sets and functions on them have to satisfy. For instance, in the lambda theory of groups, we have:
- a type
- terms
- axioms for right- and left-unit laws, right-and left-inverses, and associativity



The CCC arising from this theory has all the morphisms from the free CCC on one object and extra morphisms arising from products and compositions of the terms. A structure-preserving functor to Set assigns 
So in terminology programmers are more familiar with, the terms and axioms define an abstract data type, an interface. The functor gives a class implementing the interface. But this implementation doesn’t need to be computable! Here’s another example: we start with a lambda theory with a data type 



I think that in order to get a computable model, we have to use a “computability functor” (my term). If I’m right, this means that instead of taking a functor directly into Set, we have to take a functor into a CCC with no extra terms to get a “computable theory” (again, my term), and then another from there into Set. This way, since all the morphisms in the category arising from the computable theory are built out of S and K combinators, the functor has to pick an explicit program for the implementation, not just an arbitrary function. From there, whether the implementation of the S and K combinators is computable or not really doesn’t matter; we can’t get at anything uncomputable from within the language.
Now, changing gears and looking at the “programs as proofs” aspect of all this: morphisms in the free CCC on one object are proofs in a minimal intuitionistic logic, where 
A computable theory wouldn’t add any axioms, just assign names to proofs so they can be used as subproofs. And because the programs already satisfy the axioms of the computable theory, asserting the equivalence of two proofs is redundant: they’re already equivalent.

leave a comment